Deep Dive Into HyperExecute YAML
This document delivers detailed elucidations for each and every YAML flags, offering an in-depth understanding of each configuration parameter.
version
The version of HyperExecute YAML being used to run the tests. Currently there are two supported versions are 0.1 and 0.2.
version: 0.1
runson
OS on which you will run your Test. You can run your tests on Linux(linux), MacOS(mac), Windows10(win) or Windows10(win11).
runson: linux # or mac or win or win11
If you want to run a multi OS job, you can provide ${matrix.os} in this field as shown below.
runson: ${matrix.os}
matrix:
- mac
- linux
pre
All actions you need to perform before test execution, such as installing dependencies. You’ll ideally want to use this parameter to “pre” run simple commands like npm install, yarn install, mvn install etc
pre:
- mkdir -p m2_cache_dir
- mvn -Dmaven.repo.local=$CACHE_DIR -Dmaven.test.skip=true clean install
globalTimeout
The globalTimeout value determines the maximum duration (in minutes) of a Job. It can be set between 1 and 150 minutes, and has a default value of 90 minutes.
For example, if you set the globalTimeout to 120 minutes, a Job that exceed this duration will be automatically terminated. If you’re expecting that running all your test-cases despite parallelism is going to take more than 90 mins, set it to an appropriate value, for example, 120. If you have tests that run for longer than the maximum limit of 150 minutes, you need to get in touch with our support team.
globalTimeout: 90
runtime
The runtime flag is used to:
- Download and install the dependent language and framework that is needed to execute your tests.
- You can provide the language and the version you want to be installed.
Languages Supported: maven, java, dotnet, node, ruby, android-sdk, katalon and python
runtime:
language: java
version: "11"
- You can also install gauge and gradle only as an additional frameworks or tools independent of the language defined.
runtime:
language: java
version: 11
addons:
- name: "gauge"
version: "1.4.0"
- name: "gradle"
version : "7.0"
- You can also provide multiple languages and their specified versions that you want installed on your machine.
runtime:
- language: java
version: '17'
addons:
- name: gauge
version: '1.5.6'
- name: gradle
version: '7.6'
- language: python
version: '3.10'
- language: node
version: '16'
jobLabel
The jobLabel YAML key is used to add tags or labels to jobs. This allows you to search your jobs using the labels or tags assigned to them.
- Prioritize Your Job Pipeline: To prioritize your jobs, you need to add the required priority to the jobLabel key in the YAML file e.g
jobLabel: [ 'high', 'Low','medium']. With 'high' priority jobs triggered first, followed by medium priority jobs and finally low priority jobs. The values are case insensitive and the default priority is 'medium'. - You can also use it along with your existing job labels like this:
jobLabel: [ '${DATE} - ${DAY}','Foo','Bar', 'low']
failFast
FailFast feature allows you to stop running your tests in case there is a series of tests failure. failFast flag can be used to abort your job if the number of consecutive test failures for that job(jobID) across multiple tasks equals or exceeds the maxNumberOfTests value.
failFast:
maxNumberOfTests: 2
In case retryOnFailure flag is enabled in yaml, then there will be multiple retries for a failed test. In that case, only the failure of last retry will be considered to increment the test failure count.
base
This feature allows you to use one YAML as a base for another YAML file. By inheriting the configurations of the base (or parent) YAML file, you don't need to specify those fields in the inheriting (child) file again. Learn more.
base:
yamls:
- ./<baseConfiguration1.yaml>
- ./<baseConfiguration2.yaml>
sourcePayload
You can use this flag to use to define the source of your test scripts so that the scripts can directly be fetched from your git directly for execution on HyperExecute. Your test code is directly sourced from your Git provider with the help of secure access tokens and only your HyperExecute YAML file is encrypted and uploaded through the HyperExecute CLI. To learn more about how this feature works, go through this page.
sourcePayload:
platform: git
link: https://--------
ref: master
accessToken: <your_personal_access_token>
commit: <optional>
hostsOverride
This field allows you to add domain mappings which are required to be added in the local DNS entry represented by the /etc/hosts file. This is required if you want to map a custom domain name to an ip (local or otherwise) so that any requests on this domain name resolves to the provided ip on HyperExecute machines where your tests are running. For instance, suppose for a domain “example.com”, global DNS is having the entry which resolves the network call to the public IP address. With hostsOverride flag you can explicitly route the network call to a local IP address, instead of allowing the call to go through a public IP address.
hostsOverride:
- host: example.com
ip: 127.0.0.1
- host: example1.com
ip: 127.0.0.1
env
This variable can be used to define a list of key values which can be used to set runtime variables on the code execution platform i.e. machines.
env:
USERNAME: abc
PLATFORM: windows
This is helpful to set environment variables on the machine and use it in your code or install dependencies to run your test cases.
frameworkStatusOnly
Set status of scenario based on framework tests status. For instance, if you run a job where the framework uses lambda hooks to mark the status of tests and you want the status of the scenario to be based on the status of the tests, you need to set frameworkStatusOnly : true in the yaml. This flag will consider the status of the tests and will use this status to mark the status of scenarios giving you the ability to control the status of stages based on test status.
testSuiteTimeout
It is used to set the timeout on all scenario stages in a task. If defined, your complete test suite should get executed within this time. Its max value is 150 minutes. If you want to increase this time beyond the default maximum limit of 150 minutes, you need to contact the support team.
testSuiteTimeout: 30
In the above example, your scenario stage should finish within 30 mins otherwise the task and Job would get marked as timed out after 30 minutes of execution.
testSuiteStep
It is used to timeout individual scenario stages in a task. Each scenario in separate tasks should get completed before this time. If you want to increase this time beyond the default maximum limit of 150 minutes, you need to contact the support team.
testSuiteStep: 15
In the above example, if any of your scenario stages take more than 15 minutes to execute, then it will get timed out .
retryOnFailure
Retry on failure would allow you to set up automatic retries in case of a failed test scenario.
If set to true, then it will retry tests based on the maxRetries key as defined below.
Default value is false.
For instance instead of running your whole job again to make sure whether a test scenario actually was failing or having some issue. Using retryOnFailure will allow you to have test retires just in time of a failure to understand whether the test was actually failing or passed in consecutive attempts.
retryOnFailure: true
maxRetries
MaxRetries is the number of retries that can be done if your scenario failed. This key is used along with retryOnFailure key. If retryOnFailure key is set to true, then this key indicates the number of retries for each scenario.
retryOnFailure: true
maxRetries: 2
With maxRetries and retryOnFailure you need not have to rerun your job to retry the test scenarios, instead your test scenarios are re-tried just in time.
The maximum number of times your tests can be retried. You can allocate a numerical value between 1 and 5 for this field.
maxRetries: 2
retryOptions
Regular Expressions provides more granular control over when test retries are triggered. You can achieve this through retryOptions flag.
- You can specify precise error patterns using regular expressions to determine which errors should initiate retries.
- It works seamlessly with Cypress, CDP, and Selenium framework tests.
- It is supported in both YAML 0.1 and 0.2
Configuration:
- Set
retryOnFailure: trueto activate the retry feature. - Indicate the maximum number of retry attempts with
maxRetries: <number>. - Within the
retryOptionssection, create anerrorRegexpsarray to list the regular expressions that represent the errors you want to trigger retries.
retryOnFailure: true
maxRetries: 3
retryOptions:
errorRegexps: ["org.openqa.selenium.NoSuchElementException"]
testDiscovery
The testDiscovery key is used to locate or discover relevant tests via class names, filters, file names, etc.
testDiscovery:
type: raw
mode: dynamic
command: grep 'public class' src/test/java/hyperexecute/*.java | awk '{print$3}'
It contains the following attributes:
type
#(Recommended). When we are passing a command to discover tests.
type: raw #or
#(Advanced). For more advanced use cases.
type: automatic
type:raw
- Purpose: Perform a basic test discovery based on the provided command.
- Functionality: Directly executes the specified command and displays the discovered tests.
- Limitations: Doesn't utilize any built-in logic or advanced discovery capabilities.
- Suitable for: Simple test discovery scenarios where the command directly identifies the desired tests.
type:automatic
- Purpose: Utilize backend logic to discover tests using external tools.
- Functionality: Relies on a backend tool, such as Snooper, to perform test discovery.
- Limitations: Cannot be used directly with a command-based approach.
- Suitable for: Complex test discovery scenarios where advanced logic or external tools are required.
In summary, type:raw is a basic and straightforward approach for discovering tests based on a specified command, while type:automatic provides more flexibility and advanced capabilities by leveraging external tools and backend logic.
mode
#test discovery happens on machine where CLI is running
mode: static #or
#test discovery happens on HyperExecute VMs
mode: dynamic
command
The command that fetches the list of test scenario that would be further executed using the value passed in testRunnerCommand
command: grep 'public class' src/test/java/hyperexecute/*.java | awk '{print$3}'
Note: Test orchestration will happen with
mode: staticonly.testDiscoveryworks with yamlversion 0.1and if you are not running in matrix mode.
Dependent Test Case Discovery
Dependent tests signify that one test relies on the outcome of another. To achieve this, TestNG offers the 'dependsOnMethods' attribute within @Test annotations.
For instance, consider the code snippet in which 'SignIn()' depends on 'OpenBrowser(),' and 'LogOut()' depends on 'SignIn().'
import org.testng.annotations.Test;
public class DependsOnTest {
@Test
public void OpenBrowser() {
System.out.println("The browser is opened");
}
@Test (dependsOnMethods = { "OpenBrowser" })
public void SignIn() {
System.out.println("User has signed in successfully");
}
@Test (dependsOnMethods = { "SignIn" })
public void LogOut() {
System.out.println("The user logged out successfully");
}
}
To discover and manage dependent tests using the Test Discovery command, you can use the following syntax:
mvn test -Dmode=discover -Dplatname=win -Dframework=testng -Ddiscovery=dependent
This command will provide a Test Discovery Result that lists the tests and their dependencies, ensuring that dependent tests are executed in the correct order, such as ["Test1#SignIn,Test1#LogOut,Test1#OpenBrowser"].
preDirectives
This is an advanced version of pre where you can control how your pre commands should be executed in a parallel HyperExecute Task. If both pre and preDirectives flags are provided at the same time, then the precedence is given to the preDirectives flag.
preDirectives currently has the ability to take the following additional inputs:
maxRetries: You can retry the commands that failed in the pre-step by using this directive. The numerical value assigned to this field determines the amount of times you can retry the failed pre commands.commands: actual commands that needs to run likenpm installormvn installshell: shell to execute the commands under. This is typically helpful if you want to run your pre commands in a specific shell. For example,powershellfor Windows orbashfor Linux and MacOS.
preDirectives:
commands:
- mkdir -p m2_cache_dir
- mvn -Dmaven.repo.local=$CACHE_DIR -Dmaven.test.skip=true clean install
maxRetries: 3
post
All actions you need to perform after all test executions, such as printing an output file, uploading a report through curl API request. You’ll ideally want to use this parameter to post run simple commands like echo <some-dir>/output/output.log etc
post:
- echo <some-dir>/output/output.log
- curl https://www.example.com
postDirectives
This is an advanced version of post where you can control “how” your post commands should be executed in a parallel HyperExecute Executor. If both post and postDirectives flags are provided at the same time, then the precedence is given to the postDirectives flag.
postDirectives currently has the ability to take the following additional inputs:
commands: actual commands that needs to run likeecho <some-dir>/output/output.logshell: shell to execute the commands under. This is typically helpful if you want to run your post commands in a specific shell. For example,powershellfor Windows orbashfor Linux and MacOS. (Coming Soon)
postDirectives:
- cat yaml/win/*.*hyperexecute_autosplits.yaml
alwaysRunPostSteps
Problem : Test scenarios failing led to the cancellation of post-steps, incomplete cleanup, being unable to upload reports, and other actions that you need to perform after all test executions.
Solution : The alwaysRunPostSteps flag ensures that post-steps execute even if the scenario stage fails.
alwaysRunPostSteps: true
cachekey
It is a unique identifier that enables HyperExecute to store and retrieve cached results efficiently. When you run your tests for the very first time, HyperExecute caches the dependency files (e.g., package-lock.json, pom.xml, etc.). Now, when you execute the same test suite again (without making any changes), HyperExecute searches for a matching cached result within its cache storage, and if a valid cached result is found, HyperExecute utilizes it directly, skipping redundant execution.
{{ checksum "package-lock.json" }}
If you are using Windows as well, then also you can define the path of the cache file using forward slashes if your file is inside the directories as shown below:
{{ checksum "dir1/dir2/package-lock.json" }}
cacheDirectories
It is used to cache a certain set of files which are not supposed to change frequently such as dependency files for your tests (e.g. node_modules, .m2). HyperExecute can cache such files to help speed up your test execution time further the next time you run your job.
cacheDirectories:
- .m2
NOTE: In version 0.2 YAML, the support for caching is by default, the user does not need to specify any directories to cache for faster performance. For example, in Maven, we cache the entire .m2 directory in the home folder so that subsequent tasks run faster.
If the user adds the cacheDirectories and cacheKey keys in his YAML, the default caching gets disabled and preference is given to the user specified cache.cacheKey: '{{ checksum "pom.xml" }}'
cacheDirectories:
- .m2
projectName
This flag is used to set the Name of your Projects which would later allow you to see all jobs of that Project at one place.
projectName: '<Your Project Name>':'<Your Project ID>'
differentialUpload
When you are working with relatively large codebases, and constantly updating and upgrading your test scripts. Getting them onto the HyperExecute platform for every run might consume extra time.
To overcome this challenge, you can use differentialUpload flag, which is used to minimize the time taken to upload the codebase, especially when there are incremental changes.
This flag optimizes codebase uploads by fetching only the parts of the codebase that have been updated or newly added, significantly reducing upload times.
Configuration
enabled (boolean): Set to true to activate the optimization, and false to maintain the default behavior.
ttlHours (integer): Specifies the Time-To-Live (TTL) for the uploaded code. Users can control the duration for which the optimized upload remains active, with valid values ranging from 1 hour to 360 hours.
When you pass the differentialUpload flag, it ensures that whenever you upload the same codebase a second time with less than 75% changes, only the modified or new parts are fetched. The rest is mapped to the previously uploaded version of the codebase. This approach is beneficial in scenarios where network issues or a large codebase contribute to slow upload times.
NOTE: The default value for ttlHours is 60 hours
project:
name: XYZ Name
differentialUpload:
enabled: #true/false
ttlHours: #int value, with possible range of values [1 hour to 1440 hours]
If the project flag is not passed then the name for the project will be set to "Default Project".
By activating this feature, you can experience a significant reduction in upload times, enhancing the efficiency of running and debugging multiple jobs on HyperExecute.
report
This allows you to download the test reports generated by running your test suites on VM. You can download the report either from the jobs detail page or you can pass –download-report flag in the job triggering command from HyperExecute CLI. For using this feature, provide report: true, and the relative path of the report where your test suite generates report, type, frameworkName inside partialReports as shown in below example.
report: true
partialReports:
location: target/surefire-reports/html
type: html
frameworkName: extent
You can also email the generated report by adding email key in partialReports, below frameworkName. Learn more
report: true
partialReports:
location: target/surefire-reports/html
type: html
frameworkName: extent
email:
to:
- johndoe@example.com
Note: Set
defaultReportas false in the framework if you are using yamlversion 0.2and you want to generate a report usingpartialReportsas shown below.framework:
name: maven/testng
defaultReports: false
errorCategorizedOnFailureOnly
The errorCategorizedOnFailureOnly flag allows you to control the behavior of error categorization after the job execution based on stage status.
By default, error categorization is applied to each stage, regardless of the stage's status. This means that error categorization is generated for every stage, regardless of whether it succeeds or fails.
When you enable this flag as mentioned below, the error categorization will only be generated for stages that are not green.
errorCategorizedOnFailureOnly: true
mergeArtifacts
It is used to combine the artifacts created under each task to one.
mergeArtifacts: true
uploadArtefacts
It uploads the artifacts generated from running the tests, these artifacts are uploaded, preserved and can be downloaded once the job ends.
uploadArtefacts:
# Will upload your reports from target/site/** to HyperExecute as FinalReport
- name: FinalReport
path:
- target/site/**
# Will upload your Surefire reports from target/surefire-reports/**to HyperExecute as Surefire Report
- name: Surefire Report
path:
- target/surefire-reports/**
You can use the flag
--download-artifacts-zipto download the single zip file for all the artifacts that are generated.
linkValidity
The linkValidity flag is used to customize the duration of validity for report and artifact URLs generated after job completion. Currently URLs are inherently valid for 48 hours post-generation but you can tailor the validity period to align with the specific requirements, ensuring you can access the associated resources within the defined timeframe.
Note: If
linkValidityis not defined or 0, then the default link validity to access the artifacts and reports is 2 days. The maximum validity is 60 days.
report: true
partialReports:
location: target/surefire-reports/html
type: html
frameworkName: extent
email:
to:
- johndoe@example.com
linkValidity: 5
uploadArtefacts:
- name: ExecutionSnapshots
path:
- <path of artifact>
email:
to:
-
linkValidity: 5
stripParentDirectory
When mergeArtifacts is true, providing this flag will strip the parent directory from all the downloaded artifacts and place the artifacts in the base path.
stripParentDirectory: true
generateArtifactAfterEveryStage
With this flag artifacts will be generated after every stage,without this flag artifacts are generated after every task and avoid any overrides for artifacts of the same name.
generateArtifactAfterEveryStage: true
taskIdentifierInNonConflictingArtifacts
This flag when set to true specifies that the task ID should be included in the non-conflicting artifacts. The non-conflicting artifacts are those artifacts that can be safely shared between tasks. By default, the task ID is not included in the non-conflicting artifacts.
When the
taskIdentifierInNonConflictingArtifactsflag is set to true and themergeArtifactsflag is also set to true, the task ID will be appended to all the filenames of artifacts. This is done to ensure that the artifacts can be uniquely identified.For example, if you have a task that creates a file called index.html, and the
taskIdentifierInNonConflictingArtifactsflag is set to true, the file will be renamed to index.html.task-id. This ensures that the file can be uniquely identified, even if it is merged with other files called index.html from other tasks.
mergeArtifacts: true
taskIdentifierInNonConflictingArtifacts: true
If the
taskIdentifierInNonConflictingArtifactsflag is set to false and themergeArtifactsflag is set to true, the task ID will only be appended to the filename if the filename already exists. This is done to avoid appending the task ID to the filename of an artifact that already exists.For example, if you have a task that creates a file called index.html, and the
taskIdentifierInNonConflictingArtifactsflag is set to false, the file will not be renamed. However, if you have another task that also creates a file called index.html, the second task will rename its file to index.html.task-id
mergeArtifacts: true
taskIdentifierInNonConflictingArtifacts: false
smartGrid
If enabled, it will try to reduce the browser setup time [currently only for windows]. Default value is false.
smartGrid: true
After a test is run, it caches the browser name, version, and all the capabilities used for this particular state and test case. When running a test case, it tries to fetch from cache, which browser was used for the next stage in the previous run, and launches that browser in the background. This makes sure that, when the next test is run, the browser session is already running.
If you feel that browser setup time is more than expected, you should enable this feature. However, please note that it will reduce the browser setup time of the next test only if the current test takes enough time to launch the browser for the next test in background.
This would work only for version 0.1 and static discovery mode.
As this is dependent on the previous run of a job, any change in the browser capability or test name or test order might render the cache invalid. And browser setup time reduction might not be visible in this run, rather, it would appear in the next run.
Note : Currently this is available for Windows - edge, firefox, chrome - recent 5 versions. Linux and MAC are not supported currently.
scenarioCommandStatusOnly
When enabled, it will mark the scenario as passed even if no test is associated with it or will mark the status of scenario based on the status of the scenario executed. This can be utilised for advanced use cases where teams want to define status in HyperExecute platform based on there needs of custom frameworks.
There are two scenarios associated with it:
Scenario 1: When Sessions do not open up for certain scenarios:
- For certain scenarios that do not open up a session hence no tests are associated with that scenario, because of this the scenario gets marked as skipped and the task as partially completed. Need a way to mark those scenarios as completed/passed instead of skipped and see a green tick instead of a grey tick.
Solution : When scenarioCommandStatusOnly is set true in YAML, it will mark the task as passed even though no test is associated to it. In the given screenshot task 8 is passed even though no test is associated to it.
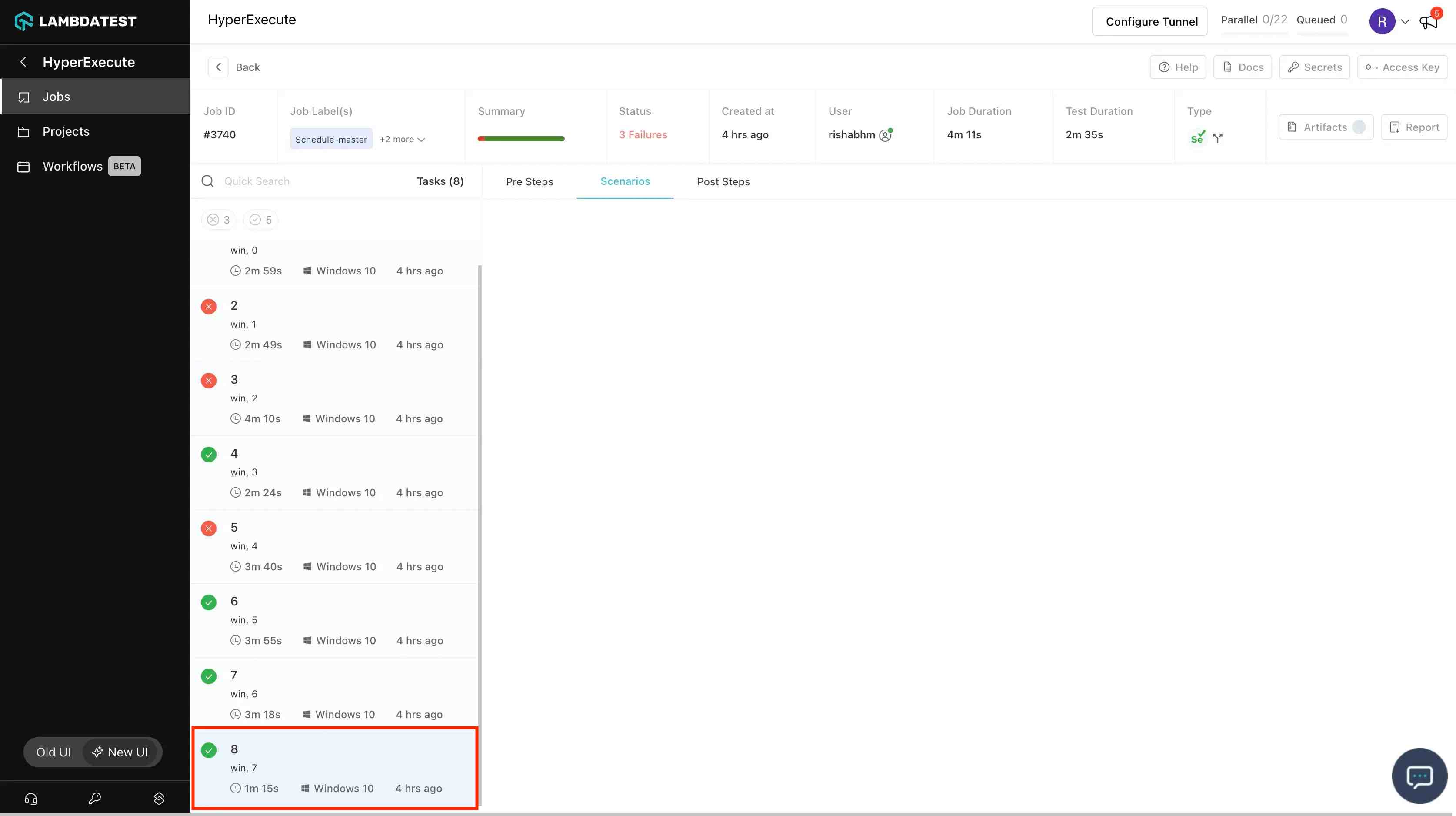
Scenario 2: When test cases are run n no of times:
- Some times a user might runs some test cases n no of times inherently due to framework retries etc. Those test cases are considered as separate entries for us, and if one fails, scenario is marked as failed and hence the task and job is marked as fail. Need a way to update status of the task as if a test case first fails and then passes, it should be shown as passing and with green tick. Currently it shows as failed.
Solution : When scenarioCommandStatusOnly is set true in YAML, it will mark the status of scenario as passed.
| Test | Edge Case | Working Case |
|---|---|---|
| Test 1 | Passes | Passes |
| Test 2 | Failed | Failed |
| Test 2 Retry - (Actually Test 3 for us) | Failed | Passes |
| Test 3 | Passes | Passes |
| Final Status of Stage | Failed | Success |
As seen in the screenshot, when one of the tests is marked as failed while the other tests are marked as passed, the overall scenario is marked as passed.
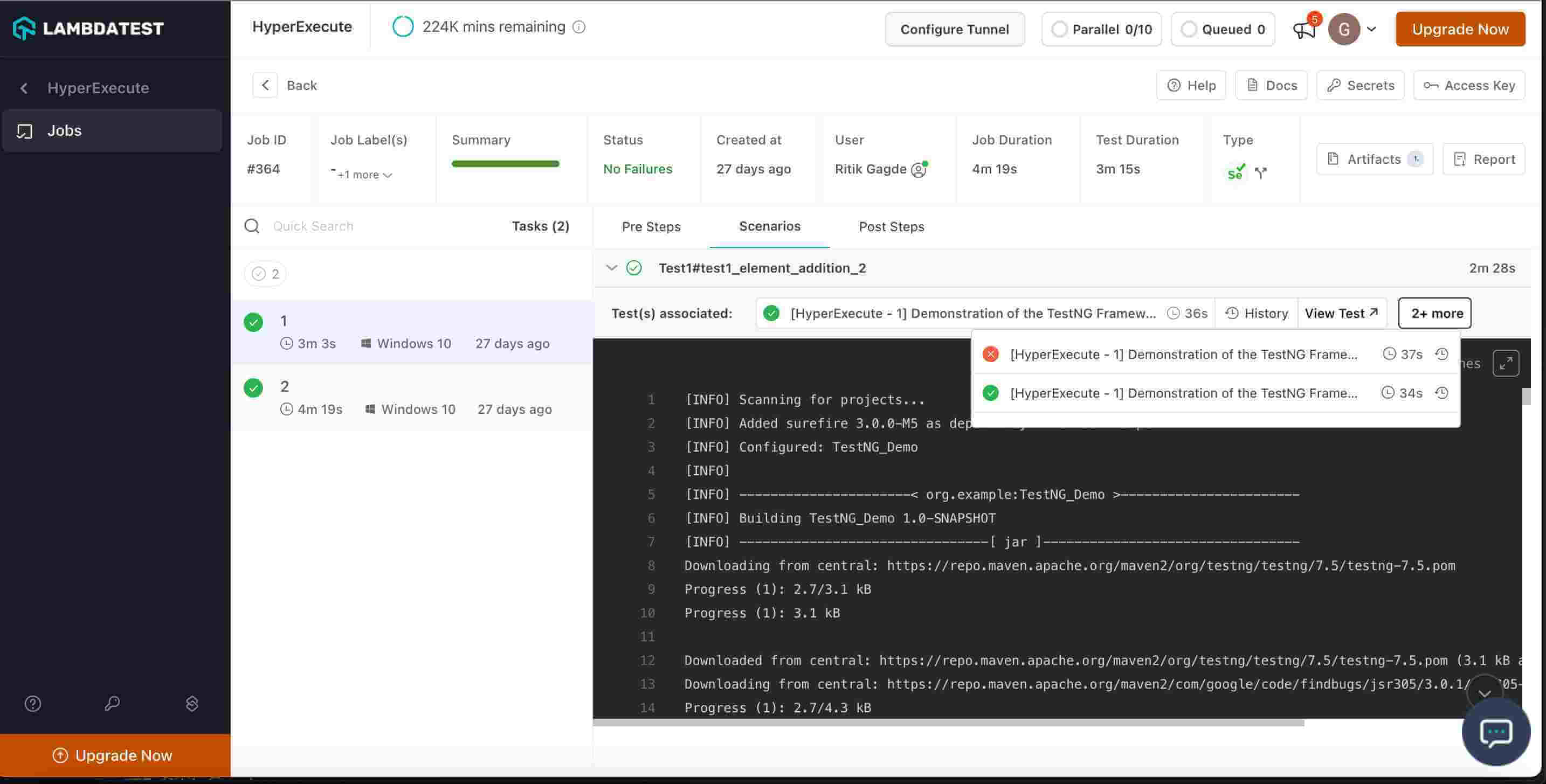
skipArtifactStageIfNoTest
It is used to gracefully handle the scenario stage inside the tasks in which there are no selenium/cdp tests executed. Instead of marking the artifact stage as failed (if artifacts are not found at the defined location, HyperExecute marks it as failed) and hence the task and job as failed, the stage would be marked as skipped and hence task and job as skipped.
skipArtifactStageIfNoTest: true
cypress
This option signifies that the test suite is a cypress test suite and should be pass as true in case of cypress suite.
cypress: true
cypressOps
This parameter is used to pass cypress specific options from the CLI. Learn more
Additional options include:
- Dedicated Proxy: This is a boolean parameter to be passed in cypressOps. When enabled user’s traffic will be passed to a dedicated proxy server, this feature has to be enabled from customer support team.
- Network: This is a boolean parameter which when set to true enables network proxy logs for the test.
- GeoLocation: This parameter is used to pass the test traffic through a specific geolocation. Value to be passed here is geolocation code
cypressOps:
dedicatedProxy: true
build: "test_03"
tags: ["a", "b"]
buildTags: ["t1"]
network: true
geoLocation: IN
shell
Shell defines the shell/terminal type on which all of the commands defined under pre, post, testRunnerCommand mentioned in yaml should run. If shell is also defined under PreDirectives then for PreDirectives command that shell would be used.
shell: bash
dataJsonPath
DataJsonPaths helps to distribute data/configs over the VMs. In this you can create a json files and put configurations/data required for your suite as json array inside the file. For example:
[
{
"Username": "user1",
"Password": "pass1"
},
{
"Username": "user2",
"Password": "pass2"
}
]
Access the JSON file Data:
To access the data from the JSON files, there are primarily 2 methods:
1. By reading the JSON file
In the JSON file, we have a data object and not an array of objects, hence you can directly read the data from the file.
{
"Username": "user1",
"Password": "pass1"
}
2. Using via env variables
You can use the env variables to access the defined parameters as:
STATIC_DATA_1_<ParameterName>
NOTE:- In the above syntax, 1 represents the file passed in the yaml file and not the data object within the file.
For instance, to access data from file1.json, the syntax would be:
STATIC_DATA_1_Username
Similarly, to access the data from the second file i.e file2.json:
STATIC_DATA_2_Username
strict
If strict is set to true in yaml then the variables used in yaml must be present in either vars or environment variables on the user machine. If not present then only a warning is displayed. But in case of strict: true, the execution will throw an error.
codeDirectory
Defines in which directory all of your commands defined in yaml would run. Your code would be downloaded in this directory.
NOTE: This features will be deprecated after Decemeber 2023.
cacheTestURL
It enables you to cache static test files in the browser.
cacheTestURL: true
In case your test, loads some URLs which can be cached but the server or browser’s configuration prevents these static files from being cached in the browser, you can enable cacheTestURL in these cases.
For instance,
if your test loads jquery static library multiple times and for some reason it is getting downloaded each time. Enable cacheTestURL to cache it. It will decrease file load time from the second time onwards.
Note: These cached resources are not yet shared across VMs. So, each VM has its own copy of cache.
afterAll
It is used to run commands after the job has finished. Currently only local directive is allowed, means that all the commands would be run on the same host on which HyperExecute CLI was run. Running commands in afterAll on HyperExecute VMs(remote commands) is not yet supported. Users will have access to all the artifacts when these commands would be run.
afterAll:
local:
commands:
- stitch-artifacts.sh artifacts-directory
For instance you want to further process the artifacts and create a custom PDF. You can use afterAll for this purpose wherein custom commands can be invoked. Other use cases can be in case you :
- Want to run some commands after the job is finished.
- Want to run these commands from the same host from which hyperexecute-cli is run.
captureScreenRecordingForScenarios
If this key is set to true, it will record whole scenario execution, and then video is accessible from your HyperExecute dashboard. This can be majorly used for non selenium based tests to have the recorded video of the whole scenario.
captureScreenRecordingForScenarios: true
buildConfig
This is used to manage hyperlink behavior based on test status. Here's a breakdown of the parameters within buildConfig:
buildPrefix: This parameter sets a custom prefix for dynamically generated build names. The format employs ${name} as a placeholder, which will be replaced with a specific value during configuration.buildName: This parameter allows you to define a specific name for the build. Similar to buildPrefix, ${name} acts as a placeholder for a custom value.buildConfig:
buildPrefix: myCustomBuildPrefix-${name}
buildName : "name=${name}"The value for ${name} in the above command can be passed through the vars command either by the CLI as mentioned below or through YAML.
Dynamic Build Naming via CLI
If you prefer to set buildPrefix and buildName values through the command-line interface (CLI), the following commands can be used:
To set buildPrefix:
--labels buildPrefix --vars "name=xyz"
To set buildName:
--labels buildName --vars "name=xyz"
These commands utilize --labels to specify the parameter being configured and --vars "name=xyz" to define the value to be replaced for ${name}.
Key Pointers
Build Configuration Handling:
If
buildConfigis not provided, then thebuild_idcolumn within the job table remains empty. When you specify thebuildConfig, it populates thebuild_idcolumn with the corresponding value.Build Configuration Precedence:
When both
buildConfigand thebuildcapability are defined,buildConfigtakes priority.Priority of Build Naming Parameters:
If both
buildConfig.buildNameandbuildConfig.buildPrefixare specified, preference is given tobuildPrefix.Association with Build Name:
Defining
buildNameassociates test results with the designated name, enabling organized tracking and management.Dynamic Build Creation:
Specifying
buildPrefixresults in the creation of a new build for each executed job. The build name format follows buildPrefix-{jobID} to ensure uniqueness.Compatibility of Build Naming Variables:
Both
buildPrefixandbuildNameare compatible with vars and can be used together or independently based on your requirements.
captureCSVResult
By enabling the boolean yaml directive captureCSVResult, you can get the statistics of the time taken by Selenium Commands run across the job. It will gather the time taken by the Selenium commands, calculate the aggregated info for the statistics like Average, 95, 99 percentiles etc and publish it in the form of a separate artifact.
captureCSVResult: true
Below mentioned custom Lambda hooks are also required to be added in the Selenium script: lambda-start-timer=<some_label> lambda-end-timer=<some_label> These custom lambda hooks are basically used to track the amount of time taken by the Selenium command.
Above performance stats artifact would be of the CSV format with headers as Label, Average, Min, Max, Median, P95, P99. Here is a brief information about these headers:
- Label: Identifier passed in the custom lambda hook to identify the Selenium command
- Average: Average time taken by the Selenium command across the whole job
- Min: Minimum time taken by the Selenium command across the whole job
- Max: Maximum time taken by the Selenium command across the whole job
- Median: Median of the time taken by the Selenium command across the whole job
- P95: 95th percentile of the time taken by the Selenium command across the whole job
- P99: 99th percentile of the time taken by the Selenium command across the whole job
Here is the sample code showing how we can use the above mentioned Lambda hooks:
((JavascriptExecutor) driver).executeScript("lambda-start-timer=t1");
/* Add 5 items in the list */
Integer item_count = 15;
for (int count = 1; count <= item_count; count++)
{
/* Enter the text box for entering the new item */
elem_new_item.click();
elem_new_item.sendKeys("Adding a new item " + count + Keys.ENTER);
Thread.sleep(2000);
}
Object t1 = ((JavascriptExecutor) driver).executeScript("lambda-end-timer=t1");
System.out.println(t1);
Note: t1 will denote the time taken by each selenium command between start and end.
matrixEnvPrefix
When we run a job in matrix mode, we set the keys with their resolved value as env variables in the scenario being run. The keys are not prefixed and hence, in some cases, we had found out that some variables like “os” can affect your test runs (for example in dotnet build commands). So, if one has an os key in matrix, it may affect dotnet build command if one doesn’t set the matrixEnvPrefix: true in yaml to have the “os” key of matrix available to us as `HE_ENV_os
dynamicAllocation
When we set dynamicAllocation true, the test cases are distributed among parallels at the runtime. This is valid in case of static test discovery. In this case, the parallels are utilised in the most optimised manner.
dynamicAllocation: true
collectLocalGitData
It is a default flag which captures the git information of your repository that you have used to trigger the job in HyperExecute which are later utilized in AI-based Root Cause Analysis (RCA) generation. In order to turn off the collection of any git information after executing your HyperExecute jobs, you can define the value false.
collectLocalGitData: false,
background
This feature allows you to run long-running Application Server tasks like "running a webapp" or a "my-sql database server" in the background.
To enable this feature from the YAML file you can use either of the below mentioned methods:
1. Using backgroundDirectives
backgroundDirectives:
shell: bash
commands:
- name: YOUR_SERVICE_NAME
command: npx static-server
- name: Database
command: mysql-server
It contains the following attributes:
The
shellproperty defines the terminal it should use to run the background service.The
commandproperty specifies the command to be executed in the background.The
nameproperty specifies the name of your Background Service.
2. Using background
background:
- npx static-server
- mysql-server
To learn more about it, refer to the Background Service page.
vars
This method allows you to name your variables. This will make the process of modifying the YAML file easier. You can use these variables in the YAML file as ${your_variable_name}. Below example shows how to use vars keyword and how to use the variables define under it at other places in yaml.
vars:
test: e2e
framework: net5.0
runtime: win-x64
testPath: ${test}\bin\build\${framework}\${runtime}
preDirectives:
Commands:
- echo ${framework}
You can also use the vars method using the CLI.
tunnel
Indicates whether to enable a tunnel for accessing your applications which are locally hosted or behind a firewall. The cli will launch a tunnel as sub process if tunnel is set to true
tunnel: true
tunnelOpts
The options to use when running the tunnel.
| Options | Type | Description |
|---|---|---|
args | List of strings | The arguments to pass to your tunnel. For a list of arguments checkout our tunnel flags |
preOnly | Boolean | Should the tunnel be enabled for only the pre step. Default false. |
postOnly | Boolean | Should the tunnel be enabled for only the post step. Default false. |
global | Boolean | Should the tunnel be enabled for all the steps? Default true. |
systemProxy | Boolean | Should the tunnel be OS system wide? Default false. |
checkTunnelOnFailure | Boolean | Check tunnel on failure adds a check on our system to check the tunnel connection if a test fails and the tunnel is set to true. This option will retry the test 2 times if tunnel connection is flaky. |
--expose | This flag takes arguments in the form of service_name:host_name_host_port. When you trigger a test, there are environment variables exposed in the machine with the variable name :- 1. service_name_PROXY_HOST 2. service_name_PROXY_PORT |
tunnel: true
tunnelOpts:
args:
- "--verbose"
tunnel: true
tunnelOpts:
preOnly: true
#------OR------
postOnly: true
#------OR------
global: true
#------OR------
systemProxy: true
pre:
- echo %LT_PROXY_PORT%
- echo %LT_PROXY_HOST%
- echo %MYSQL_PROXY_HOST%
- echo %MYSQL_PROXY_PORT%
tunnel: true
tunnelOpts:
args:
- "--expose mysql:localhost:3306"
tunnelNames
Specify the list of already running tunnel names which you want to use for accessing your applications which are locally hosted or behind a firewall.
tunnelNames: ["lambdatest_tunnel"]
testRunnerExecutor
When utilizing the testRunnerCommand to execute a job on a Windows Virtual Machine, the default behavior is to run the command in PowerShell. However, in situations where test names include special characters, you may encounter an error like below.
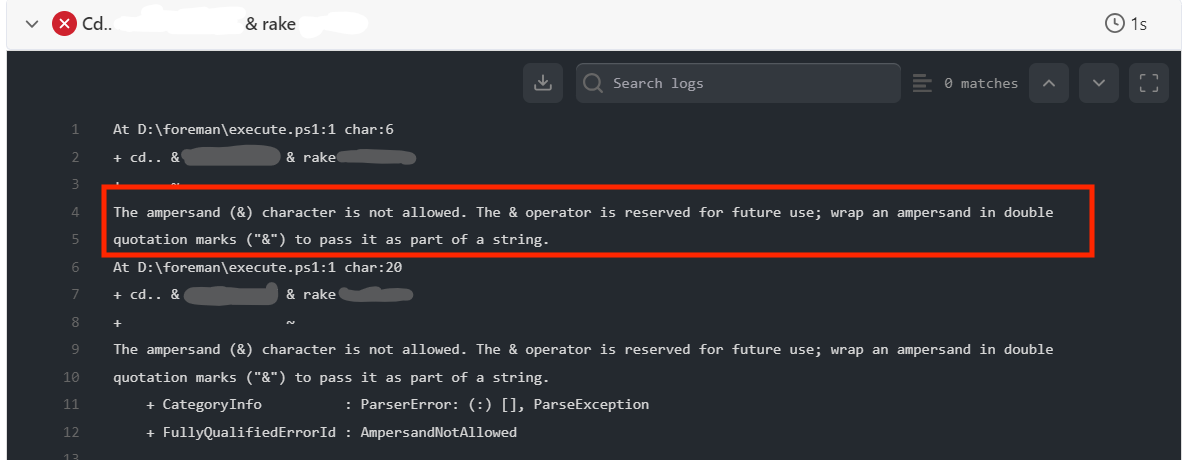
To address this, it is necessary to include this specific flag to switch the test execution from powershell to the command line as intended.
testRunnerExecutor: bat
workingDirectory
The working directory specifies the location of the directory in which all test discovery and execution commands will be run, as well as the location of any files or directories that are created as a result of the command execution. If the workingDirectory option is not specified, then the working directory will be the directory where the YAML file is located.
framework:
name: maven/testng
discoveryType: method
workingDirectory: src/main
flags:
- "-Dplatname=win"
autosplit
Setting autosplit to true will distribute the scenarios among the concurrent number of tasks.
If you want to distribute you m commands on n VMs automatically and you don’t need to bother much about which all commands are grouped together on a single VM, you can use the autosplit feature for this purpose.
For instance, you have a parallelism of 10 and you want to run 50 commands in total. Using autosplit, the system will distribute these 50 commands on 10 Vms in the most efficient manner possible. Each VM(task) will receive some commands to run out of these 50 commands.
Note: In
static mode, these commands will be distributed among VMs smartly(AI) using history data, such that each VM(task) gets to run for almost the same amount of time. This is to reduce the totaljobtime.
If your Auto Split test has to be enabled, set this boolean value to true. For more information on the Auto split feature, go to this page.
autosplit: true
concurrency
Indicates the number of concurrent tasks to run on HyperExecute for processing all your scenarios and/or test-cases. A HyperExecute job, thus triggered, creates as many threads as the value provided for this key. Required for autosplit.
concurrency: 10
Pro Tip: The platform will guide you to utilize a higher concurrency automatically after analyzing your usage and test cases. You can find this information on the left side banner. Learn more
Note: You can see the overall concurrency trends using our analytics widgets. Learn more
testRunnerCommand
The testRunnerCommand is a command used to run a single test entity in isolation. This entity could be a file, module, feature, or scenario. It is defined in the YAML file and tells the system how to run the test entity.
#For example
testRunnerCommand: mvn test -Dcucumber.options="$test" -Dscenario="$test" -DOs="win 10"
This command runs the test using Maven and passes in the options for Cucumber, the scenario to run, and the operating system to use.
Note: This is only required in yaml
version 0.1and if you are not running in matrix mode.
#Another example
testRunnerCommand: npm test -- $test
macTestRunnerCommand
In hybrid mode, you can run your tests on multiple OS using the same yaml. On different OS testRunnerCommand can be different. So for specifying specific commands for MAC OS in hybrid mode. You can use this command.
macTestRunnerCommand: mvn test -Dcucumber.options="$test" -Dscenario="$test" -DOs="mac"
winTestRunnerCommand
In hybrid mode, you can run your tests on multiple OS using the same yaml. On different OS testRunnerCommand can be different. So for specifying specific commands for Windows in hybrid mode. You can use this command.
winTestRunnerCommand: mvn test `-Dcucumber.options="$test"` `-Dscenario="$test"` `-DOs="win 10"`
linuxTestRunnerCommand
In hybrid mode, you can run your tests on multiple OS using the same yaml. On different OS testRunnerCommand can be different. So for specifying specific commands for Linux in hybrid mode. You can use this command.
linuxTestRunnerCommand: mvn test `-Dcucumber.options="$test"` `-Dscenario="$test"` `-DOs="linux"`
Note: If the OS specific command is not provided then the testRunnerCommand will be used by default. If both are not provided then you will get an error.
matrix
A matrix allows you to create multiple tasks by performing variable substitutions in a single job. For example, you can use a matrix to create more than one version of a browser, operating system, etc. For more information on Matrix multiplexing strategy, go to this page this page.
matrix:
files: ["Test1","Test2","Test3"]
combineTasksInMatrixMode
The concurrency flag is not acknowledged in matrix mode. Therefore, you must set combineTasksInMatrixMode to true if you wish to use a limited number of concurrencies that are available in your license for a matrix-mode job. Instead of using one machine per matrix combination, this will run the (matrix-multiplied) combinations as scenarios in the number of HyperExecute machines that was specified in concurrency.
For example, the below-mentioned YAML snippet will generate a total of 8 scenarios, and since the concurrency is set to 2, these 8 scenarios will run in parallel on 2 HyperExecute machines. In each machine (let's say each has 4 scenarios to execute), they will be running sequentially only.
Total Scenarios = [Entries in os List] x [Entries in browser List] x [Entries in Files List]
concurrency: 2
combineTasksInMatrixMode: true
matrix:
os:[mac, linux]
browser:['edge', 'brave']
files: ['Test1', 'Test2']
testSuites
A command to run the tests that were mentioned in the scenario key for matrix based test execution. Learn more.
testSuites: - mvn test -Dtest=$files
parallelism
If we mention runson: ${matrix.os}, then we need to make sure that parallelism is defined as well. There are 2 ways to define parallelism, either you can mention common parallelism which can be used in any platform or you can mention platform specific parallelism ex - winParallelism, linuxParallelism etc.
parallelism: 2
matrix:
os: [win, mac]
version: [1, 2, 3]
browser: [chrome]
In the above example we have total of 3 combinations for each os i.e. For win: Version: 1, Browser: Chrome Version: 2, Browser: Chrome Version: 3, Browser: Chrome For mac: Version: 1, Browser: Chrome Version: 2, Browser: Chrome Version: 3, Browser: Chrome
So each combination will run on a parallelism provided in the yaml. Here all combinations will run on a parallelism of 2.
macParallelism
It is used if you want to provide different parallelism for MAC OS. If mac parallelism is not present it will consider parallelism as the default value.
parallelism: 2
macParallelism: 3
matrix:
os: [win, mac]
version: [1, 2, 3]
browser: [chrome]
In the above example windows combinations will run on a parallelism on 2 and MAC combinations will run on a parallelism defined by macParallelism i.e. 3.
winParallelism
It is used if you want to provide different parallelism for win os. If win parallelism is not present it will consider parallelism as the default value.
parallelism: 2
winParallelism: 3
matrix:
os: [win, mac]
version: [1, 2, 3]
browser: [chrome]
So in the above example mac combinations will run on a parallelism on 2 and windows combinations will run on a parallelism defined by winParallelism i.e. 3
linuxParallelism
It is used if you want to provide different parallelism for linux os. If linux parallelism is not present it will consider parallelism as the default value.
parallelism: 2
linuxParallelism: 3
matrix:
os: [win, linux]
version: [1, 2, 3]
browser: [chrome]
So in the above example windows combinations will run on a parallelism on 2 and linux combinations will run on a parallelism defined by linuxParallelism i.e. 3
Note : For platform if both is missing then the CLI will throw an error.