
A Deeper Insight into Test Design
Istvan Forgacs
Posted On: July 1, 2022
![]() 12311 Views
12311 Views
![]() 10 Min Read
10 Min Read
Test automation is a hot topic, test design isn’t. However, without appropriate test design, test automation is worthless as you will execute test cases several times without detecting the bugs in your software. Test design is one of the most important prerequisites of quality. Test design is necessary for:
- evaluating the quality of the product with regards to customer expectations and needs (quality control)
- finding defects in the product (testing).
Fortunately, or unfortunately, it is a creative process on its own, but also one that requires technical expertise.
“More than the act of testing, the act of designing tests is one of the best bug preventers known. The thinking that must be done to create a useful test can discover and eliminate bugs before they are coded – indeed, test-design thinking can discover and eliminate bugs at every stage in the creation of software, from conception to specification, to design, coding and the rest.” Boris Beizer Software Testing Techniques (1990).
Steps of test design
- First, the test approaches are worked out, which means that it should be planned how the product quality together with the cost optimization goals can be achieved, taking into consideration the elicited test conditions, code complexity, and risks. At this point, the test approaches are approximated from a technical point of view: technical consistencies with standards, processes, flows, measures, user experience, etc.
- After planning the test approach, the test design techniques are selected that meet the testing objectives and the result of risk and complexity analysis. In general, it is advisable to select test design techniques understandable by other stakeholders. Real systems usually require using more techniques in combination. Below you can see the test design classes and the most important test design techniques. There are some techniques (in bold) that are not involved in any ISTQB material. I will make a separate blog for each of them, and here I include only a very short overview of them.
Test design class Test design technique Specification-based Equivalence partitioning Boundary value analysis General predicate testing Decision table testing Cause and effect graphing Classification tree method Combinatorial testing Combinative testing State transition testing Action-state testing Scenario-based testing Random testing Metamorphic testing Syntax testing Structure-based Statement testing Branch testing Path testing Decision testing Branch condition testing Modified condition/decision coverage Data flow testing Structure-based Error guessing Error guessing Exploratory testing Session-based testing Checklist-based testing Model with execution-based Use case testing with execution Action-state testing with execution Fault-based Mutation testing General predicate testing (GPT) is a reliable extension of boundary value analysis when there are more logically dependent requirements given. By applying general predicate testing all the potential predicate bugs will be revealed. It’s easy to use as almost the entire method can be automated. GPT’s test selection criterion requires that each border be covered by four test cases: (1) a test input “closest” to or on the boundary that is inside the examined domain (ON point), (2) the closest test to the border that is outside the examined domain (OFF point), (2) a data point inside the examined domain that differs from the ON point (IN point) and (4) a data point outside the examined domain that differs from the OFF point (OUT point). Many points for different borders can be merged.
Combinative testing: The rationale behind the combinative technique is to assure that for a single variable each computation is calculated in more than one context. The basic variant of combinative testing is called diff-pair testing. Informally, it requires that each value p of any parameter P be tested with at least two different values q and r for any other parameters. In this way, the number of test cases remains linear with input space, yet trickier bugs can be detected.
Action-state testing is a step-by-step technique where abstract steps are created one by one, controlled by a simple algorithm. Instead of making the whole model at once, it is made gradually. It can be considered as a union of use case testing and state transition testing. Action-state testing consists of steps. One step consists of a user action, a system response, and a test state. The method does not need guard conditions, therefore it’s a true codeless solution for test design automation.
Metamorphic testing “is an approach to both test case generation and test result verification. It is a property-based software testing technique, which can be an effective approach for addressing the test oracle problem and test case generation problem. The test oracle problem is the difficulty of determining the expected outcomes of selected test cases or determining whether the actual outputs agree with the expected outcomes. A central element is a set of metamorphic relations, which are necessary properties of the target function or algorithm concerning multiple inputs and their expected outputs.”
Model with execution technique: The first step is to create an abstract model. Abstract test cases can be generated from this model. The abstract test cases contain the minimum information for a tester to execute the tests. For example, add items to reach EUR 30 is appropriate, as a tester knowing the requirements can do it. When the application is ready, the tester executes the test cases and validates the results. The concrete inputs and outputs are recorded. Therefore, there is no need for exact input/output as in the case of specification-based techniques. Only validation is necessary.
Mutation testing is actually a method for ‘testing the tests’. During mutation testing alternative codes, i.e., mutants are created. The test cases we’ve designed should distinguish the basic program under test from all the alternative programs so that for one test some outputs can be different. Therefore, to distinguish the correct code from all its alternatives, test cases should be designed to differentiate the correct code from all its faulty alternatives. Each alternative/mutant is a textual modification of the code and can be generated or created manually.
- The next step is to determine the test case selection criteria (for simplicity we refer to this as test selection criteria). The test selection criteria determine when to stop designing more test cases, or how many test cases have to be designed for a given situation. The test selection criterion for the equivalence partition method, for example, may result in designing a different number of test cases for each equivalence class. It is possible to define different (“weaker” or “stronger”) test selection criteria for a given condition and design technique.
- The next step is to establish the test data. Test data are used to execute the tests, and can be generated by testers or by any appropriate automation tool (can be produced systematically or by using randomization models). Test data may be recorded for re-use (e.g. in automated regression testing) or may be thrown away after usage (e.g. in error guessing).
Typically, test data are created together with the test case they are intended to be used for. Test data can be created manually, by copying from production or legacy sources into the test environment, or by using automated test data generation tools. Note that concrete test cases may take a long time to create and may require a lot of maintenance. - Now we can finalize the test design. A test case template contains a test case ID, a trace mapped to the respective requirement/test condition, test case name, test case description, precondition, postcondition, dependencies, test data, environment description, expected result, actual result, priority, status, expected average running time, comments, etc. Of course, you can omit what is not relevant.
- The next step is to design the test environment. The test environment consists of items that support test execution with software, hardware, and network configuration. The test environment design is based on entities like test data, network, storage, servers, and middleware. The test environment management has organizational and procedural aspects: designing, building, provisioning, and cleaning up test environments requires well-established procedures.
- Finally, you should validate all the important artifacts produced during the test design including the control of the existence of the bi-directional traceability between the test basis, test conditions, test cases, and procedures.
Characterization of test design techniques
To evaluate the different test design classes, we should characterize them. I tried to collect the main characteristics that determine a test design class.
- Input – the key element of designing the test case is to plan the appropriate inputs. For example, considering the Boundary Value Analysis technique we need input on the border and another input that is very close to the border but on the opposite side. Calculating the input is not easy, sometimes difficult. For specification-based class, the input should be calculated before test execution. For an experience-based class, the input is not pre-calculated just selected during the execution. Similar is the case for the model with execution class, but some high-level description gives some guidelines for input selection. Selecting the input during test execution is much easier. For structure-based class, the input should be calculated based on domain constraints which are very difficult and sometimes impossible. Finally, for mutation, there is no input needed.
- Output – For specification-based class, the output is also calculated. For experience-based, structure-based and model with execution classes, the output is only validated, i.e., you don’t need to calculate before, only check during the program execution which is much easier. For mutation testing output is just for comparison, thus it’s neither calculated nor validated.
- Implementation – We know that we should start testing as early as possible. Therefore, implementation-independent methods are better. Considering these classes, specification-based and model with execution classes are implementation-independent, the others are not.
- Exclusivity – Structure-based techniques are never used without other techniques as they would be very difficult and time-consuming. Mutation testing only validates the tests and thus cannot be used in itself.
- Effectiveness – This refers to how many bugs are detected with respect to the total number of bugs in the application. For specification-based and model with execution classes the effectiveness is high (by applying a strong test design technique in the class), for experience-based is medium. For structure-based the effectiveness is low and for mutation testing, it is not applicable as it only measures the effectiveness.
- Regression testing – It is very important as the code is continuously changing which requires re-testing the whole application. Only experience-based testing is not a regression testing method.
Based on this characterization here is a table for the test design classes:
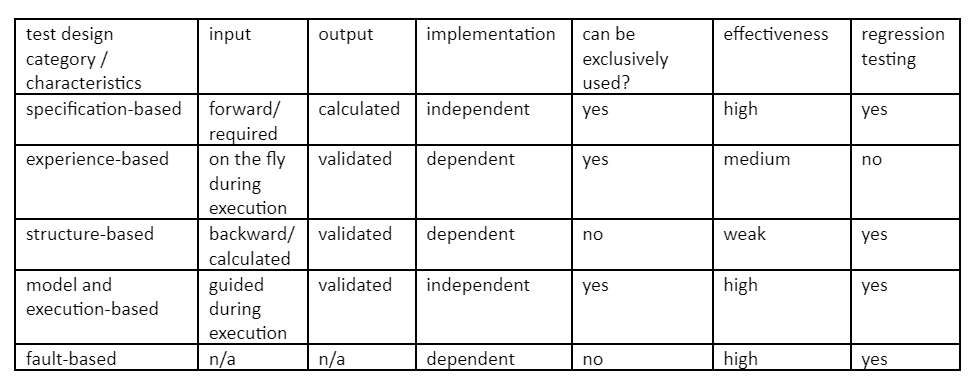
Based on this table and the above explanation we can say that the structure-based technique is not a real test design class. It is for validating the test cases designed by other techniques and for creating missing test cases due to incomplete test design or implementation-dependent code that isn’t related to any requirement. I would call it a test creation/validation method.
Fault-based mutation testing is also not a real test design technique as it is not for designing, it is only for validating the test cases.
Considering the remaining test design classes, experience-based is the easiest and fastest solution but it’s not appropriate for regression and its effectiveness is lower than the two others. The model with execution class is the best as it is effective and efficient. It can also be combined with specification-based techniques such as use case testing and action-state testing.
Conclusion
Here I overviewed test design as a very important part of software testing. I made characterizations of the different techniques and compared them based on these characteristics.


Author’s Profile
Istvan Forgacs
István Forgács PhD is an entrepreneur, a test expert and an author. He is the lead author of the book Practical Test Design and Paradigm Shift in Software Testing and the co-author of the Agile Testing Foundations. He is the creator and key contributor of the test-first, codeless test design automation tool Harmony. With his co-author Prof. Attila Kovács, they created a website that is a unique place where testers can exercise test design by executing and improving their tests. They introduced three test design techniques: combinative testing, action-state testing and general predicate testing.
Blogs: 8
Got Questions? Drop them on LambdaTest Community. Visit now












