
Test Observability – A Paradigm Shift from Automation to Autonomous to Deep Observability for Better ROI [Testμ 2023]
LambdaTest
Posted On: August 24, 2023
![]() 3272 Views
3272 Views
![]() 12 Min Read
12 Min Read
In the ever-changing software landscape, our testing methods must keep pace with the rapid developments. We’ve progressed from manual to automated and even autonomous testing. Now, a new imperative arises the need for test observability.
Test observability involves extracting real-time insights from our automated testing setup. These insights guide us in making informed choices regarding product stability, reliability, and deployment speed. By concentrating our testing resources where they are most impactful, we optimize efficiency and resource utilization. This approach offers a comprehensive view of our system’s health through automated testing.
In essence, we’re leveraging technology to maximize the value derived from testing. This empowers us to make intelligent decisions and execute tests with precision. By doing so, we harmonize our testing strategy with the rapid development cycles and the heightened expectations of our customers, ensuring a dependable and user-friendly end product.
Vijay Kumar Sharma shared insights on using technology for informed decision-making and efficient execution in value-driven testing. He emphasized leveraging data-driven insights to focus testing efforts effectively. Attendees learned about intelligent test execution and the importance of staying aligned with evolving technological trends for optimal results.
About the Speaker
With over 18 years of experience in Quality Engineering, primarily with Adobe and Sumo Logic, Vijay Kumar Sharma brings a wealth of expertise. He has been a featured speaker at multiple testing conferences in India. He intended to suggest a presentation titled Test Observability and Its Significance in the Rapidly Evolving Landscape of Technology Companies.
If you couldn’t catch all the sessions live, don’t worry! You can access the recordings at your convenience by visiting the LambdaTest YouTube Channel.
What was intended to be discussed in the live interaction?
Vijay started with the slide that presented the discussion that was planned to take over, along with mentioning his key focus area on his journey of Test Observability and how it is evolving.
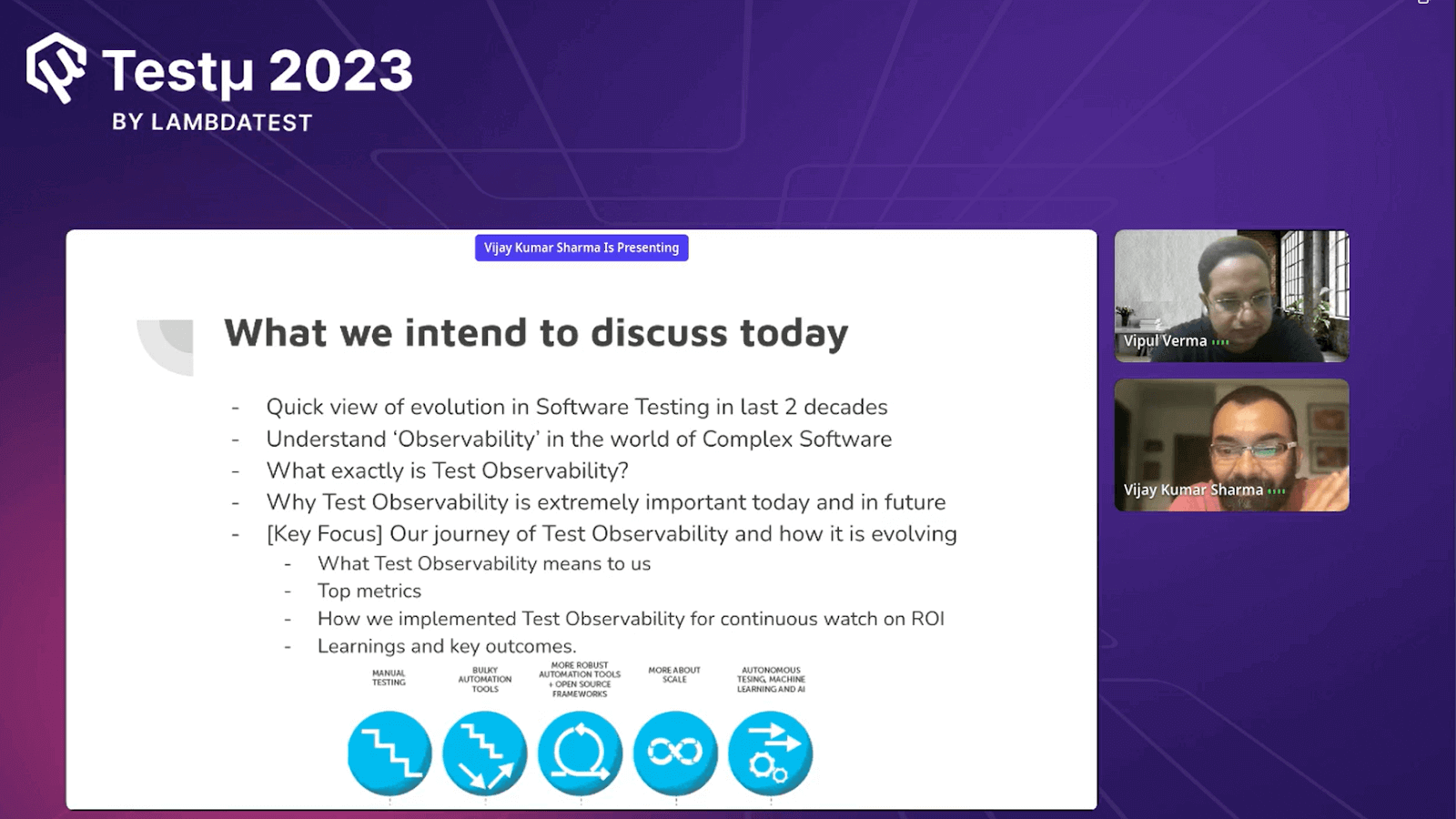
- Quick view of evolution in Software Testing in the last two decades.
- Understand ‘Observability’ in the world of Complex Software.
- What exactly is Test Observability?
- Why Test Observability is extremely important today and in the future.
- [Key Focus] Our journey of Test Observability and how it is evolving
Quick view of evolution in Software Testing in the last two decades
Shift from Waterfall to Agile, Test Automation, Continuous Integration and Continuous Deployment (CI/CD), DevOps Automation and Continuous Testing, Shift Left Testing, Microservices and Containerization, Behavior-Driven Development (BDD), Exploratory and Context-Driven Testing, AI and Machine Learning in Testing, Shift to Cloud and Mobile Testing, Security Testing and Compliance, Shift to Remote and Virtual Testing, TestOps, and Site Reliability Engineering (SRE) Shift to User-Centric Testing, Low-Code, and No-Code Testing.

Understand ‘Observability’ in the world of complex software
Observability is the ability to gain insights and understand what is happening within a system by collecting, analyzing, and visualizing relevant data.

Why is Observability important?
Observability is crucial for keeping software running smoothly. It’s like having a superpower that helps us see what’s happening inside our software. This superpower helps us fix problems quickly, make our software faster, and prevent big issues.
- Issue Detection and Resolution: Observability helps us catch problems in our software before they become big issues. It’s like finding a tiny crack in your wall before it turns into a big hole.
- Performance Optimization: Just like a coach helps athletes get better, observability helps us make our software faster and more efficient. It’s like giving our software a boost of energy.
- Root Cause Analysis: When something goes wrong, observability helps us discover why it happened. It’s like being a detective and finding out the real reason behind a mystery.
- Capacity Planning: Imagine planning a party. Observability helps us know how many people our software can handle without slowing down. It’s like making sure our party doesn’t get too crowded.
- Debugging and Troubleshooting: If our software acts strange, observability helps us find the exact problem. It’s like fixing a puzzle by finding the missing piece.
- Continuous Improvement: Observability helps us improve our software over time.
What exactly is Test Observability?
Vijay highlighted that testing is also becoming more complex with software complexity, and monitoring the test repository can be challenging to track.

- Deriving continuous insights from your automation infrastructure and using them to make crucial decisions around product stability, reliability, and speed gaps in continuous deployment.
- Helps you ensure that you spend your time and money running tests where needed and get a bird’s eye view of your entire system through these automated tests.
- Analytics for Symptoms to Root cause.
Why is Test Observability important today and in the future?
Vijay further discussed the active questions that arise when starting with Test Observability, and he provided answers to the questions that can help his audience understand what to do when some questions arise. This blog will only cover a few questions; to know more about it, watch our video, which will be live soon on the LambdaTest YouTube Channel.
Are you aware of the tests that have been failing for quite sometime? or you still in a perception that you have build a future proof product? This is where Test Observability approach can help you navigate through what potentially have been failing!#TestMuConf pic.twitter.com/ogEGr9KljX
— LambdaTest (@lambdatesting) August 23, 2023
- Aiming for 100% test coverage in a sin, but how do you find the right balance?
- What is the ROI from tests that have passed 100% in the last quarter?
- Even if there is no human effort, you are burning SS.
- What happens with tests failing 50%+ times in a quarter?
- A test with high execution frequency is failing more vs a test with Iow execution frequency is failing less?
- Among the failed tests, what are the genuine failures, and what is just noise?
- Can I ensure that genuine defects are not masked by flaky tests?
- Is there a way to debug only the unique and genuine errors that caused the failures?
- Is it possible to get to the root cause of a failure in a matter of seconds without reproducing the failure locally?
- What are the top issues plaguing my automation?
- How can I keep track of my test suite’s stability and performance metrics over time and get alerted of regressions in behavior?
While it’s nice to test everything, it’s also slow. So, it’s smarter to test the important stuff and not waste too much time on the other things. This way, you catch the big problems and use your time well.
When all tests have succeeded 100% in the last three months, the software is likely in good shape with fewer problems. This saves time and money that would otherwise be spent fixing issues, making the software more reliable.
Even without people doing anything, resources are still being used up.
When tests fail 50% of the time in a quarter, it suggests significant issues with the software that need attention.
Tests failing frequently when run often could signal serious problems needing immediate attention. Conversely, tests failing less when run infrequently might point to minor issues or stable software areas. Both cases need consideration for maintaining software quality.

Out of the failed tests, we need to determine which ones indicate actual issues and which are simply random errors or unimportant glitches. This helps us focus on addressing genuine problems without getting distracted by minor issues.
Absolutely, you can make sure that real problems aren’t hidden by unreliable tests. By identifying and fixing flaky tests that give inconsistent results, you ensure that genuine defects receive the attention they deserve, leading to a more accurate assessment of your software’s quality.
Certainly, you can focus on debugging the specific and real errors that caused failures. By analyzing patterns and identifying unique issues, you can distinguish between genuine problems and noise, effectively saving time and effort while addressing the root causes.
Yes, it’s possible to determine the main reason for a failure within seconds without needing to recreate the issue on a local system. Advanced tools and observability practices allow us to swiftly pinpoint the underlying cause by analyzing real-time data and patterns.
The main challenges affecting our automation include unreliable test outcomes caused by unstable tests, sluggish test execution causing delays, and the struggle to distinguish real defects from background noise. Solving these issues will improve the overall efficiency and effectiveness of our automated testing approach.
To track your test suite’s stability and performance metrics and receive notifications for behavioral regressions, deploy ongoing monitoring tools that capture and analyze these metrics. Configure automated alerts that activate when significant deviations from established standards occur, guaranteeing the timely identification of any declining test suite behavior.
Our journey of Test Observability and how it’s evolving?
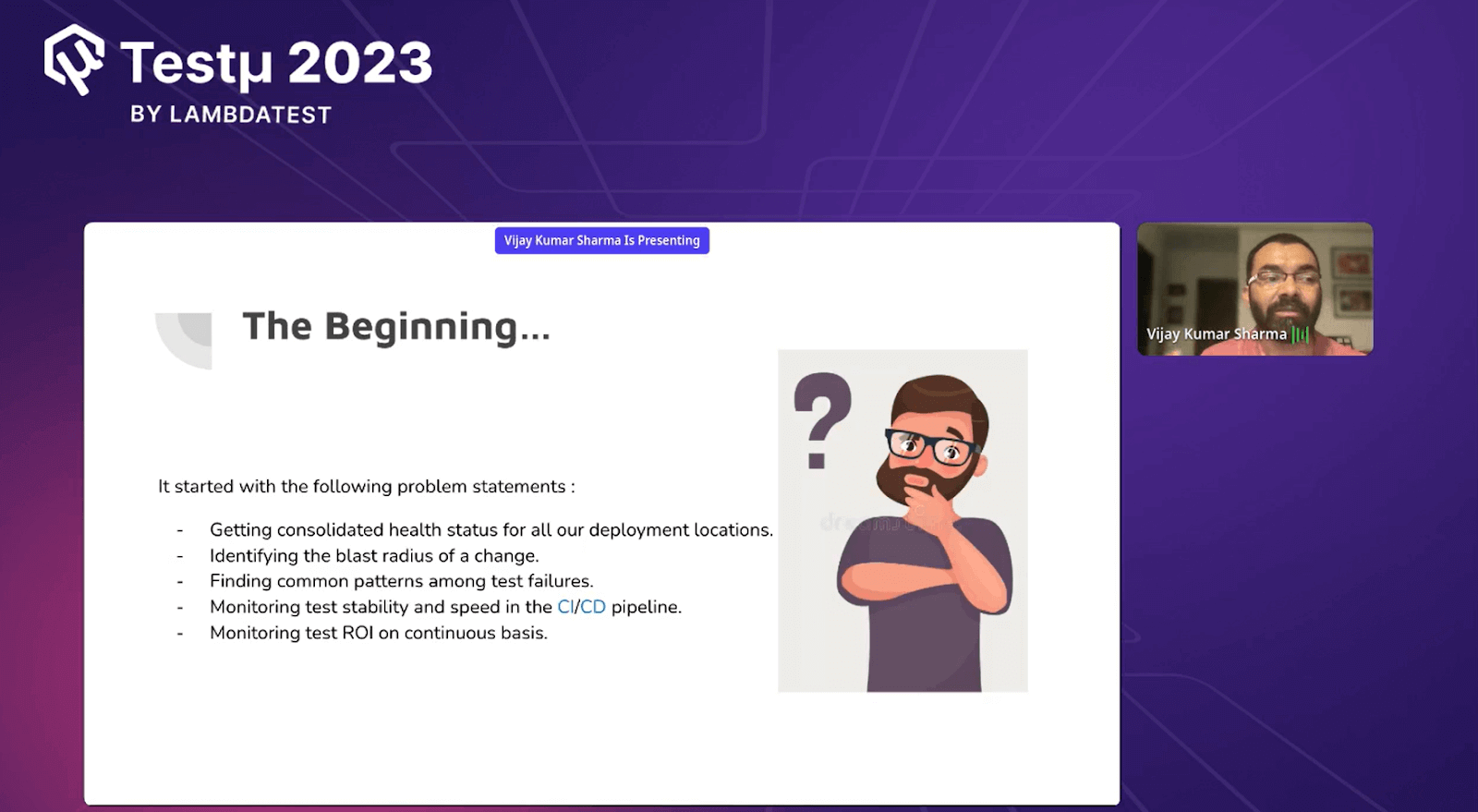
Vijay further shared the journey of Test Observability with his team by highlighting some steps that they considered at the beginning of Test Observability with problem statements.
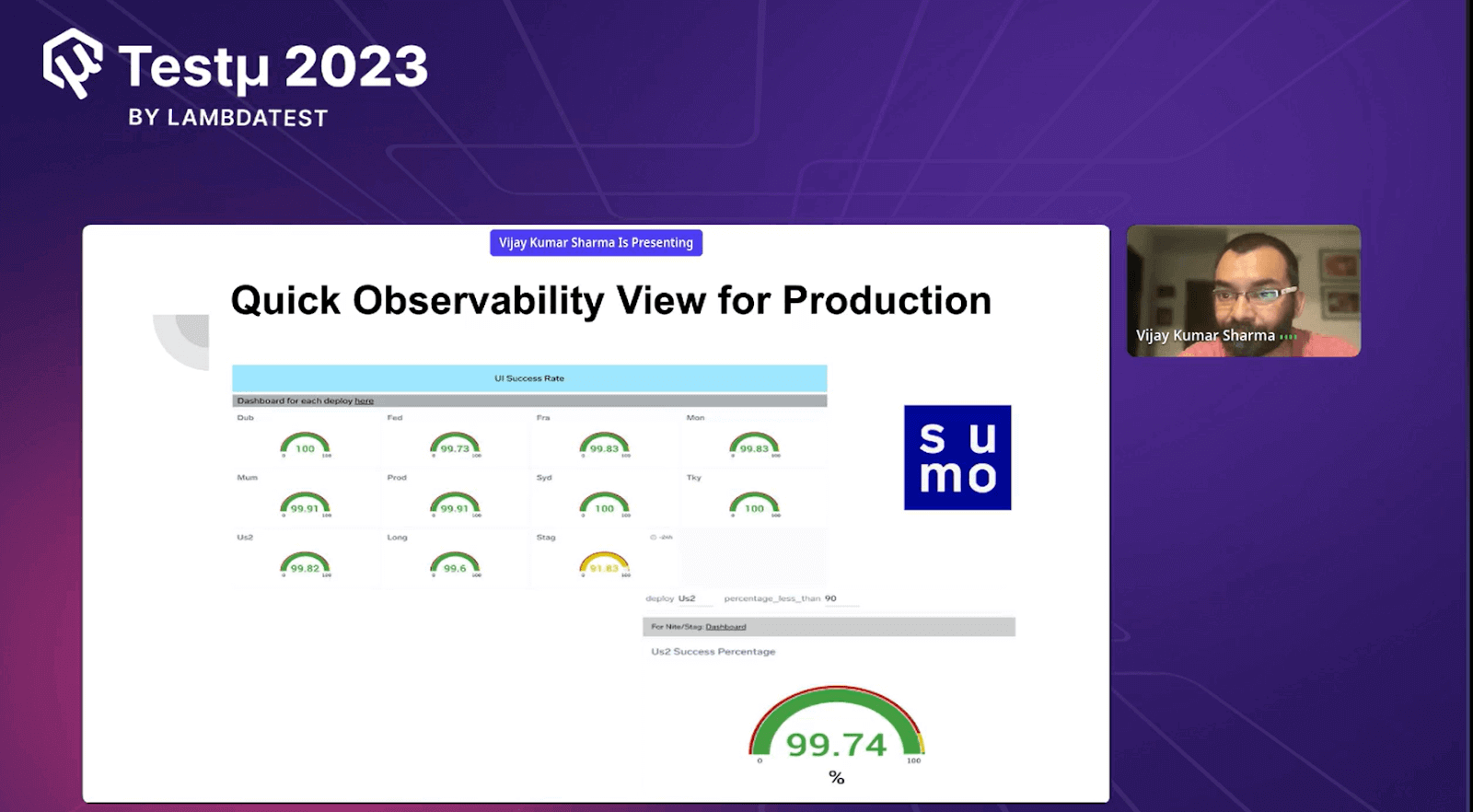
Quick Observability view for production
Vijay displayed the deployment health chart of Selenium UI tests, which are pipelined with CI/CD. Each test here gives an insight into what is happening in production.
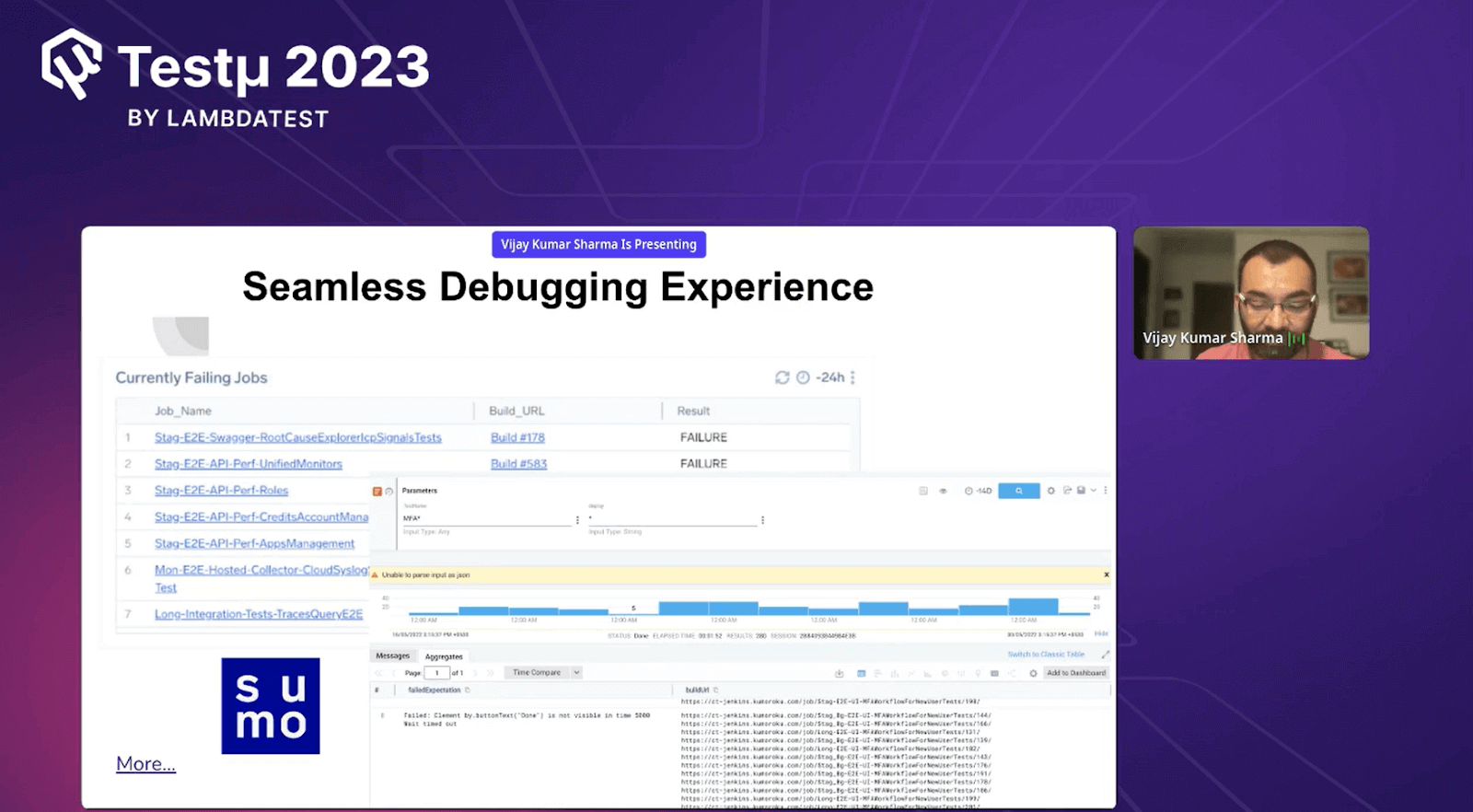
Seamless debugging experience
With this seamless Debugging feature, it is easy to identify the error causing the test to fail.
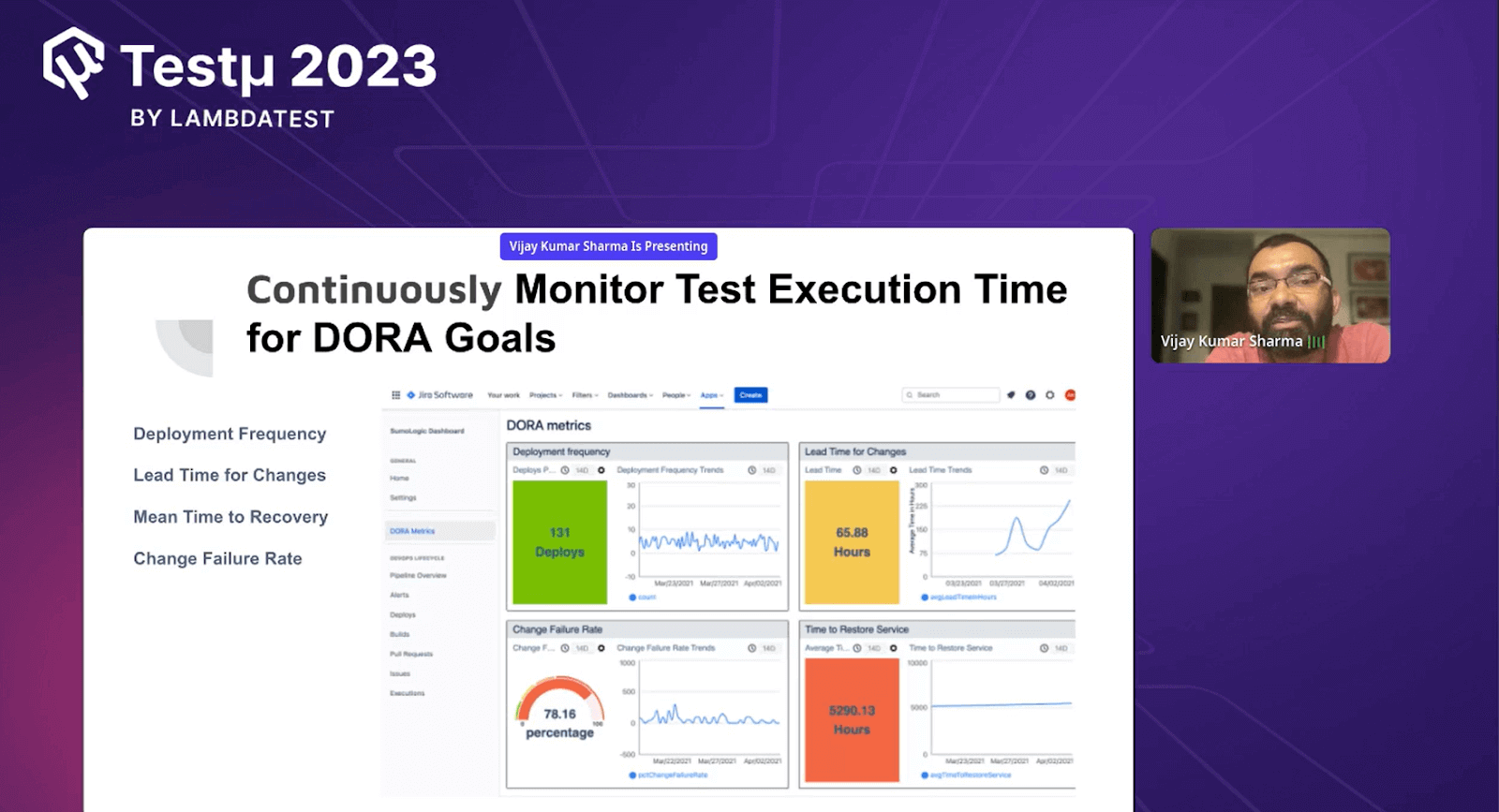
Continuously monitor test execution time for DORA goals
Vijay discussed the dashboard view present below. He highlighted that this dashboard is the integration of Sumo Logic with Atlassian. This dashboard gives the overall insight into what’s happening across the tools to monitor Deployment Frequency, Lead Time for Changes, Mean Time to Recovery, and Change Failure Rate.
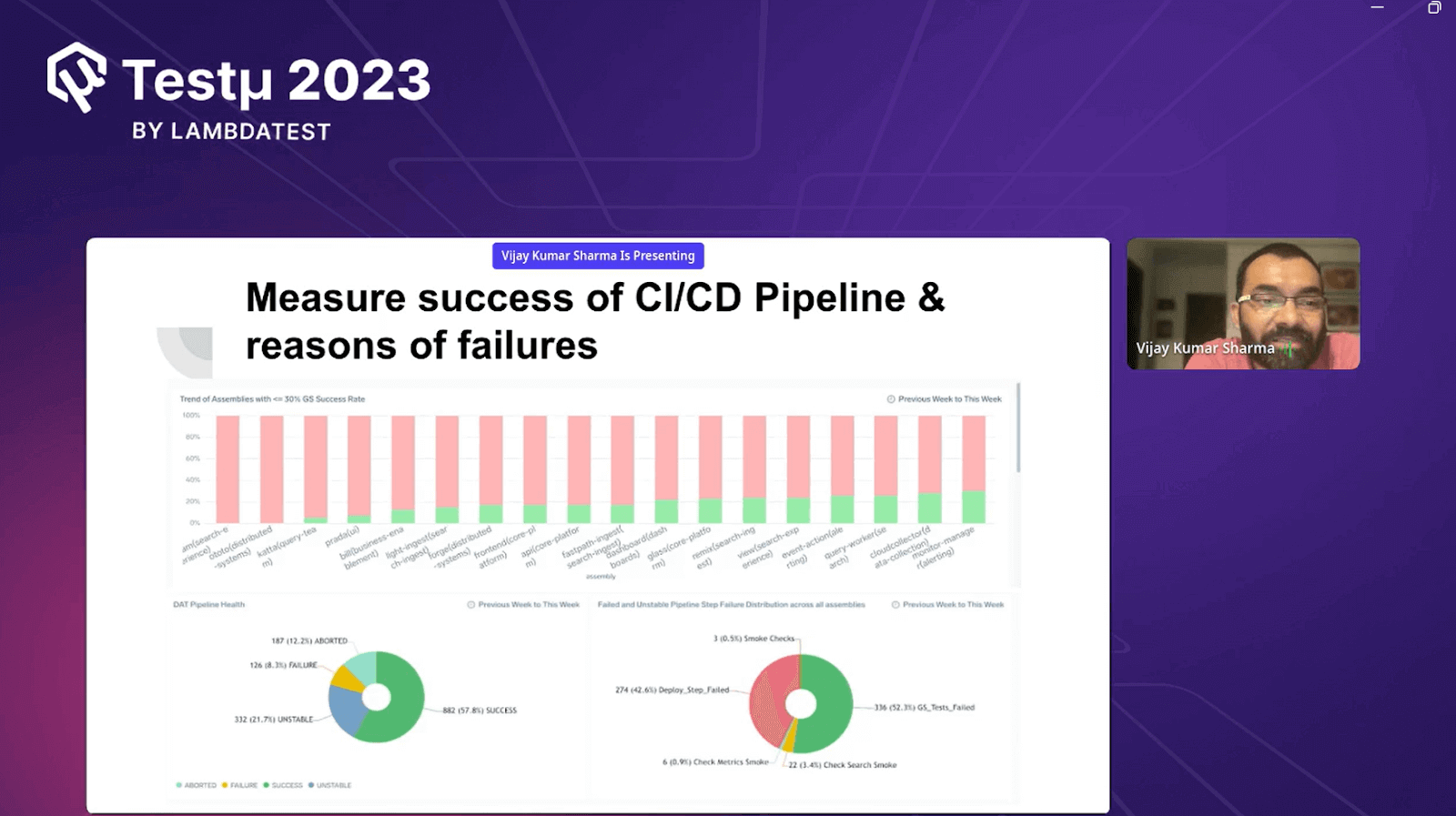
Measure the success of the CI/CD pipeline & reasons for failures
To check if your CI/CD pipeline is doing well and figure out why it fails sometimes; you need to see how often it works smoothly and what goes wrong when it doesn’t. This helps you improve your pipeline over time by fixing the problems.
Measure test flakiness and the ability to drill down
Check how often tests give inconsistent results (flakiness) and see if you can investigate deeper to find out why. This helps ensure tests are reliable and helps find the real issues.

Revisit if your legacy tests still add value
Vijay highlighted that there will be many tests that are executed, and the use of Test Observability is that you can revisit and remove some of the tests that are no longer needed. And then you can also maintain the PRs for different areas of the products and more. He mentioned that Test Observability is part of the evaluation process.

Collect all the data from different test results and use it smartly to generate insights that help you become more productive.
It was great learning about the new concept of Test Observability; Vijay closed up his session by answering a few questions from the attendees.
Q & A Session
- Can you explain how test observability can enhance testing processes and outcomes?
- What access do I need to use to test observability?
- As software systems become more complex, how does deep observability transform how organizations approach troubleshooting, root cause analysis, and continuous improvement?
- Could you share an example of a scenario where insights from test observability led to significant improvements in a software development project?
Vijay: Certainly! Test observability is like having a special tool that makes testing better. For instance, if a test doesn’t work, observability can quickly show what’s wrong in the code. It also helps us know which tests are most crucial and need attention first, making testing more effective and efficient.
Vijay: To use Test Observability, you’ll need access to tools or systems that gather information from your tests. These tools show you what’s happening in your tests, making finding and fixing issues easier.
Vijay: Deep observability can help organizations improve how they troubleshoot, analyze, and improve software systems.
Vijay: A software team used test observability to collect data on how a new feature performed during testing. The data showed that the feature was causing performance problems. The team used this information to identify the root cause of the problem and make changes to the feature. As a result of the changes, the performance problems were resolved, and the feature could be released on time. This significantly improved the project’s success because it prevented delays and ensured that the feature was released to users as soon as possible.
Have you got more questions? Drop them on the LambdaTest Community.


Author’s Profile
LambdaTest
LambdaTest is a continuous quality testing cloud platform that helps developers and testers ship code faster.
Blogs: 175
Got Questions? Drop them on LambdaTest Community. Visit now










