
Two-phase Model-based Testing
Istvan Forgacs
Posted On: November 29, 2022
![]() 10696 Views
10696 Views
![]() 6 Min Read
6 Min Read

Most test automation tools just do test execution automation. Without test design involved in the whole test automation process, the test cases remain ad hoc and detect only simple bugs. This solution is just automation without real testing. In addition, test execution automation is very inefficient.
If you write the test code in a simple way you hurt the DRY (Don’t Repeat Yourself) principle. For test automation, it means that the maintenance cost will be higher. If you use the page object model – a design pattern where the page objects are separated from the automation test scripts., the code will be much longer and takes more time to write.
That’s why advanced test automation tools include test design. As Bloor Research states: ‘Test design automation provides a potentially massive boost to testing speed and efficiency. Properly leveraged, it can also dramatically improve the end-user experience.’
The tools involving test design are the model-based testing (MBT) tools. ISTQB defines model-based testing as “Testing based on or involving models”. Thus, instead of creating test cases one by one manually, we create an appropriate test model from which an MBT tool is able to generate test cases. However, a model itself is not enough. Traditional test design necessitates the application of test selection criteria, which make it possible to know when to stop creating test cases. Therefore, an MBT tool generates test cases from the model and is based on the appropriate test selection criteria.
Modelling is a divide-and-conquer activity. Its main goal is to collect those elements of a system (at that time the requirement specification) by which the system can be reliably tested. We can make relatively simple models in a hierarchical way, and from these models, a tool can generate abstract test cases.
Systems planned by requirement specifications can be modelled in different ways. For testing, we may need special test models but in practice, software engineering models such as state transition diagrams, UML activity diagrams, EFSM, BPMN, use case diagrams, etc. are used. These are not ideal representations for creating reliable test sets.
Challenges of Model-Based Testing
A common characteristic of these models is that each can be represented as graphs (even textual models such as use cases have graph representations). Traversing the graphs in different ways, different levels of test selection criteria can be selected. The test cases can be generated to satisfy the selected criterion. Here is the advantage of using test design automation: instead of creating the test cases one by one in an ad-hoc way, they are generated based on an accepted model and test selection criterion.
One problem is that traditional models should involve information about the implementation for test code generation. This means that every event , input, and output should be in the model. If the model is created before implementation, then lots of work should be repeated according to the real implementation. Making models after implementation on the other hand contradicts the shift left principle.
Another common problem is that traditional methods require coding. Traversing a graph invalid test cases are generated. For example, adding the second item to the shopping cart, then deleting the third one is not possible. Guard conditions are added to address this problem. However, guard conditions are code. If a guard condition consists of output, then this output should be coded. If it’s a difficult function, the guard code is also difficult, and how to test it?
Generating Test Cases in Two Phases
The most popular solution is using stateless models. They can be generally used and that’s why they are the most popular and widely used MBT tools. A specific problem is that stateless models will detect only the simplest bugs even if a stronger test selection criterion has been selected (such as the all-transition-pairs criterion) see this blog post.
Stateful models such as state transition diagrams detect trickier bugs, however, they can’t be used for many systems to be implemented (states are difficult to identify or there are too many states).
All these problems can be addressed by double-phase model-based testing.
Phase 1: Generate High-Level Test cases
Here the first model is a high-level model. Abstract test cases are generated from the model. These test cases can validate the requirement before implementation. In this way, most of the bugs, misunderstandings, etc, can be removed or fixed which is very cheap at this phase of the SDLC. We call these test cases abstract as they can be executed by humans, but executable test code cannot be generated.
The high-level model consists of textual steps. Each step contains a (user action), a (system) response – optional, and a test state – optional. Actions and responses are well-known in use case testing, however, test states are significantly different from program states. The solution to reducing the huge number of states is that if two actions are the same, but the system calculates the response in different ways, then we have arrived at different states.
Example. The initial state is ‘paying is not possible’. If we add any items so that the total price remains below EUR 10, then we remain in the same state as we remain under the pay limit. However, reaching 10 we arrived at a new state ‘paying is possible’.
The reason behind the test states is that each different calculation should be tested as any of them may be faulty. In this way, the number of states remains manageable, yet the necessary tests will be involved. We validated this assertion when solving the exercises of our website and all the bugs have been found by this model.
Here is an example for modeling:
|
1 2 3 4 |
INITIAL STATE cart empty R4 paying is possible when price 10: add items so that price remains below 10 => check that price <10 STATE paying is not possible add items so that price reaches 10 => check that price =10 STATE paying is possible |
The first line is the initial state. The second line is a label that connects the requirement R4 to the model and the test case. The third line consists of a model step. The first part ‘add items so that price remains below 10’ is a user action, the second part: ‘check that price <10 ’ is a validation of the system response, and the third part ‘paying is not possible’ is the resulting test state. A tester knowing boundary value analysis will add items to the cart reaching the closest value below 10. When she validates the result, she will check that paying hasn’t been possible yet.
Executing this test step is easy for the tester knowing the prices of the items, but currently, it’s almost impossible for a machine that should know the test design techniques, understand the text of the model steps and identify the prices on the screen (or by reading and interpreting the specification).
A single test is generated from this model above consisting of the two model steps. The model can be easily modified to execute these steps in two individual test cases:
|
1 2 3 4 |
INITIAL STATE cart empty R4 paying is possible when price 10: add items so that price remains below 10 => check that price <10 STATE paying is not possible add items so that price reaches 10 => check that price =10 STATE paying is possible |
You can see that tabulation makes it possible to continue a test case or start a new one.
Model steps are truly implementation-independent. You can implement the shopping feature of these model steps in any way. The model steps are also very compact. They should contain less information which is enough for the tester for manual execution. For example, a model action change password successfully
may involve five steps to be implemented:
- click on the password change menu item
- insert current password
- insert new password
- insert a new password for the second time
- click on the submit button
In this way, the model remains compact and can be understood and reviewed easier.
Phase 2: Generate Low-Level Test Cases
The next phase is the generation of the executed test code. This can be done by manually executing the test cases. During the execution a low-level model is generated on the fly, see the figure below:
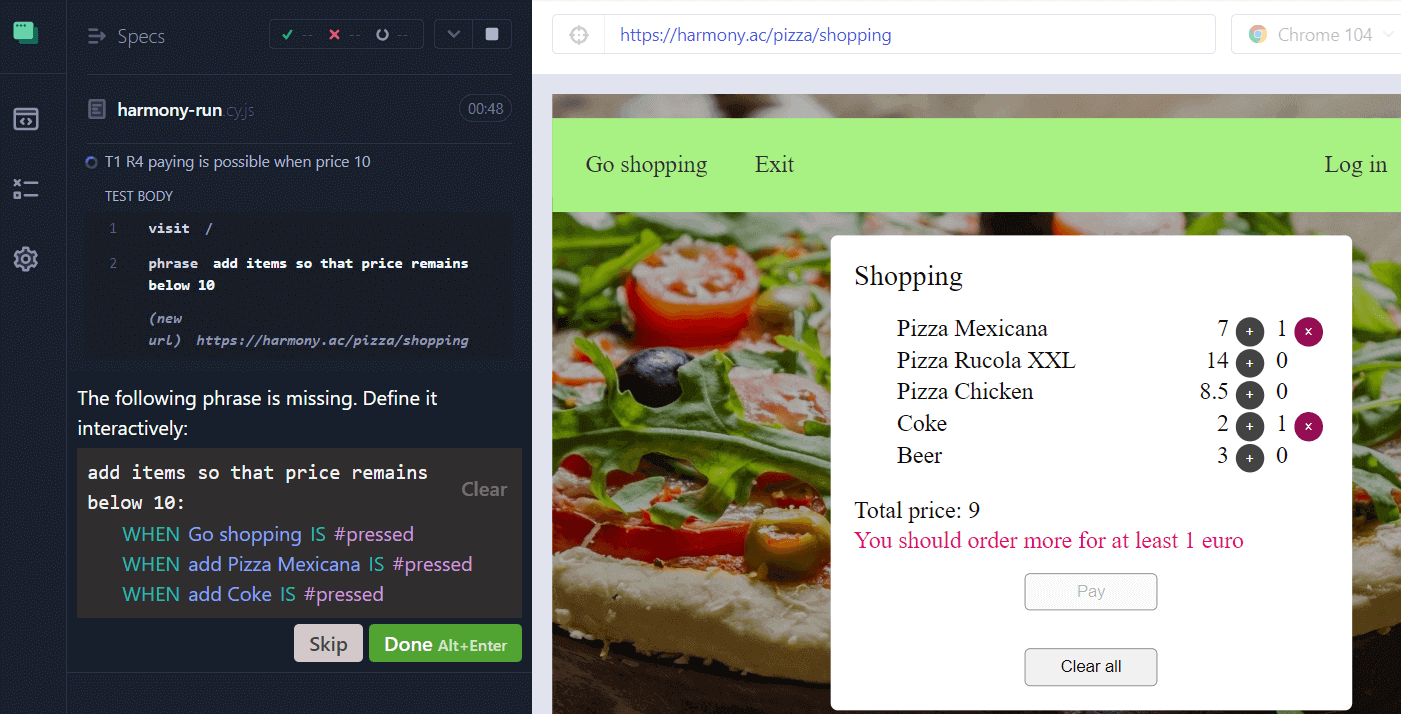
Figure 1. A low-level model is generated during the execution of an abstract test step ‘add items so that price remains below 10’
The tester executes the current actions or responses, here ‘add items so that price remains below 10’.
Here the low-level model is a Gherkin-like description but can be anything. Considering the first step:
|
1 |
WHEN Go shopping IS #pressed |
the Go shoppingis the selector that identifies the Go shopping UI element, and #pressed means a click on that. The validation is a little bit more difficult as you should select the validation type or the result itself. For example, if you want to validate that the Pay button is inactive, then you can select the pay button first, then that it is a validation (THEN), and finally the #non-active command
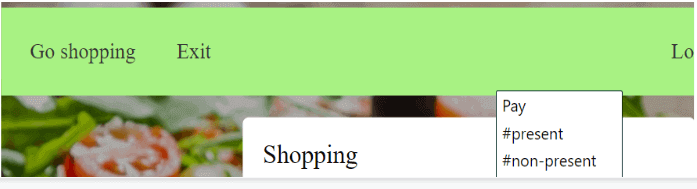
Figure 2. Validation of the Pay button is inactive
In this way, you can easily generate a low-level model that contains every piece of information for test code generation. A tool can generate test code for any programming language and any test runner.
Conclusion
A clear advantage of this method is that it’s a DRY testing solution. It means that the test cases may consist of some steps more times, but the tester will manually execute them only once as the second occurrence of the same step will be executed automatedly.
It’s a method where the automation part is entirely automated, and testers can do test design at the highest-level making models. It’s not an easy task especially if test states are involved, but it’s fun and results in higher-quality code.
The two-phase modeling is a true shift-left solution that can be used for stateful and stateless cases. It’s also an efficient defect prevention method. Test automation in this way becomes not only fast, but it’s very comfortable as testers don’t need to calculate the results in advance. They just need to check them, which is much easier. Finally, this method is for testers as it needs test design but doesn’t need coding knowledge.


Author’s Profile
Istvan Forgacs
István Forgács PhD is an entrepreneur, a test expert and an author. He is the lead author of the book Practical Test Design and Paradigm Shift in Software Testing and the co-author of the Agile Testing Foundations. He is the creator and key contributor of the test-first, codeless test design automation tool Harmony. With his co-author Prof. Attila Kovács, they created a website that is a unique place where testers can exercise test design by executing and improving their tests. They introduced three test design techniques: combinative testing, action-state testing and general predicate testing.
Blogs: 8
Got Questions? Drop them on LambdaTest Community. Visit now












