
Guide to Model Based Testing To Improve Test Automation
Istvan Forgacs
Posted On: September 14, 2022
![]() 12169 Views
12169 Views
![]() 10 Min Read
10 Min Read
Model-based testing employs models to define software/system behavior and testing strategies, aiding in designing and executing testing processes effectively. These models represent the system under test and testing environments, optimizing software and system testing approaches.
In my preceding blog on efficient test design, I showed that using model-based testing not only improves software quality, but it’s more efficient than coding test cases. Great, but there are so many model-based testing (MBT) alternatives, how can you select among them? I show you the different approaches and their advantages and disadvantages.
There are different classifications of the MBT methods. For example, the modeling languages, textual vs graphical, mode, i.e., online or offline, etc. Here I introduce another classification based on efficiency and usability in test automation. In this classification there are only three classes:
- Stateless
- Stateful
- Aggregate
Here I only consider the first two and in a subsequent blog the third one.
Stateless model-based testing
The first class of the MBT methods is the stateless MBT. Here the business processes are modeled, describing the dynamic aspects of the systems. Examples of these models are BPMN, UML activity diagrams, use cases, etc. All these solutions have different notations, but there are very similar with respect to the information they involve. All of them consist of user actions, events, and maybe system responses. It’s more important what they don’t consist of: states. Most MBT tools use this technique. These models are successfully used in software engineering and you can think that it’s a perfect solution for MBT. Unfortunately, when used for testing there are some issues.
Any stateless model can be transformed into a similar graph, see the example below. The tests are generated based on some graph traversal and test selection criteria. The first problem is that there are infeasible paths in the graph. To avoid this problem, MBT tools offer the usage of constraints. Constraints are conditions to prohibit invalid paths. For example, a constraint is when transition b cannot precede transition a.
However, sometimes guard conditions are also needed. A guard condition here describes when a given action/event can happen. This means that the modeling requires some coding. Using this method an MBT tool cannot be entirely codeless.
However, the bigger problem with these MBT methods is that as they do not consider states, they may not find even a simple bug. For example, a frequent bug is when a code location has a correct state for the first time it’s traversed but becomes incorrect during some subsequent traverses. For example, paying is not possible below 20 Euros, but adding food reaching 21, then deleting an item to go below 20, the paying remains possible.
To demonstrate stateless MBT, here is a simple example.
Here is a simple stateless (or flow) model of the requirement specification above. The edges are the user actions and the nodes are the system responses.

This model permits any valid test case as any add car / add bike / delete car / delete bike sequence can be traversed in the graph. From start, only a car or a bike can be added. Excellent, you can think that the model is good, but it isn’t.
As mentioned, there are invalid paths leading to non-realizable tests. For example, you can traverse a path of adding a car and then deleting two cars. However, the related test would result in a negative car number in the cart. In general, you can only delete existing elements from the cart. Hence, several invalid paths exist in the model and the usage of constraints is not enough.
Instead, guard conditions are needed, i.e., the modeling requires some coding. For example, the guard condition for a transition ‘delete car’ starting from other than node ‘car added’ is:
number_of_cars ≥ 1.
Hence, variables must be handled and keep them up-to-date, e.g.:
number_of_cars++ or number_of_cars–
We should add similar code and guard conditions to transitions when deleting a bike happens.
As mentioned, a more significant problem is that this method will not find some bugs that other methods will. To see why, let’s select the ‘all-transition-pairs’ criterion, where all the adjacent transition/edge pairs should be covered. Though the number of such pairs in the extended graph is numerous (16), still the tests are not reliable, i.e., will not find the bugs.
From the requirements it’s obvious that you should test the following:
T:
- Add some vehicles to add a free bike.
- Delete some vehicles until the free bike is withdrawn.
- Add some vehicles again to see if the free bike is given back.
However, the transition pairs needed to satisfy the criterion is:
- add car, add car, delete car (2)
- add car, add bike, delete car (2)
- add bike, add car, delete bike (2)
- add bike, add bike, delete bike (2)
- add car, delete car, add car (1)
- add car delete car, add bike (1)
- add bike, delete bike, add car (1)
- add bike, delete bike, add bike (1)
- add bike, add bike, delete bike, delete bike (1)
- add bike, add car, delete bike, delete car (1)
- add bike, add car, delete car, delete bike (1)
- add car, add car, delete car, delete car (1)
The first four lines cover two-two pairs, the others just one (with bold). You can see that a test set satisfying the criterion may not cover the first step of the test (add car, add car, add bike).
Therefore, even the first step of T1 will be missing. Even a stronger criterion will not detect the bug which T1 detects.
Yet, the advantage of the method is that it can be generally used, and if states are not relevant (see next chapters), then it can be efficiently used. That’s the reason that most of the model-based testing tools (CA Agile Requirements Designer and Curiosity) apply this technique.
Stateful model-based testing
Let’s do a Google search for ‘state transition testing’! All the examples contain systems with a very limited number of states such as ATM authentication, setting time and date, and switching a lamp on and off. In practice, the number of (program) states are huge and cannot be used for state transition testing resulting in millions of test cases. The only solution is to reduce the number of states. This can be done if we consider only ‘inner states’ and guard conditions.
For example, considering our requirement specification, program states involve the number of bikes and cars and some inner states. In this case, there are several states/nodes in the graph, resulting in too many test cases. We can reduce the number of states but how? An appropriate solution is to consider only the inner or test states.
In our example we have five inner/test states:
- No discount, no bike.
- No discount, bike included.
- Discount, bike added.
- Discount, bike converted.
- Stop.
The advantage is obvious: as the minimum requirement from a test set is to cover each state, the discount will be tested. The state transition graph is here.
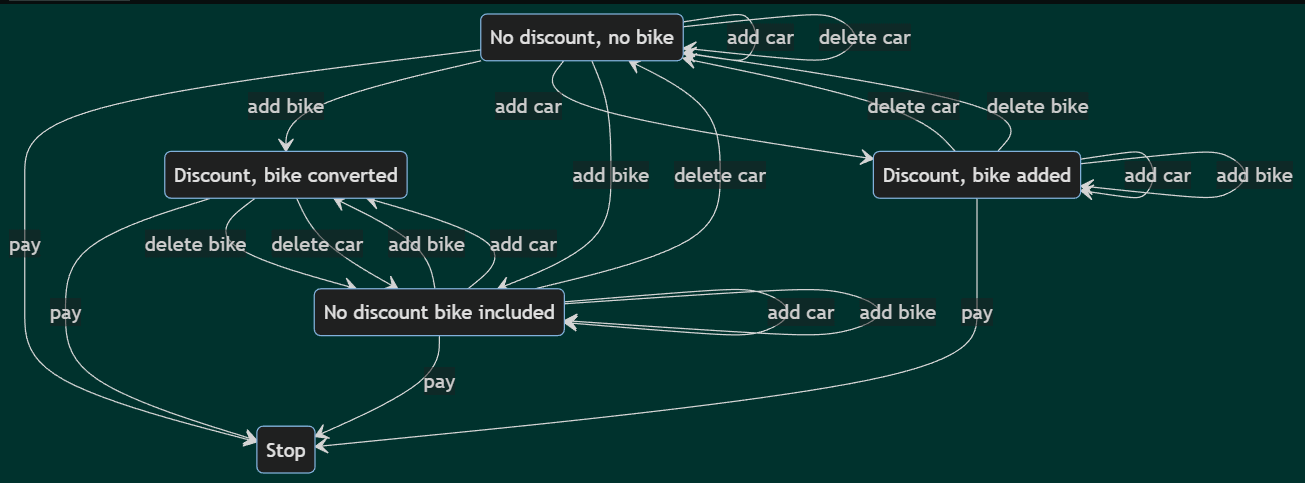
Again, let us assume that the test selection criterion is the all-transition pairs. Let’s consider our test case again:
T:
- Add some vehicles to add a free bike.
- Delete some vehicles until the bike is withdrawn.
- Add some vehicles again to see if the free bike is given back.
The first step is covered by reaching the state Discount, bike added. From here, there is a transition delete car that should be traversed. With this, step 2 is covered. As all the adjacent transition pairs should be covered, we should select add car that goes back to the state Discount, bike added. This means that to satisfy our criterion, test T should be added, see this pair emphasized below:
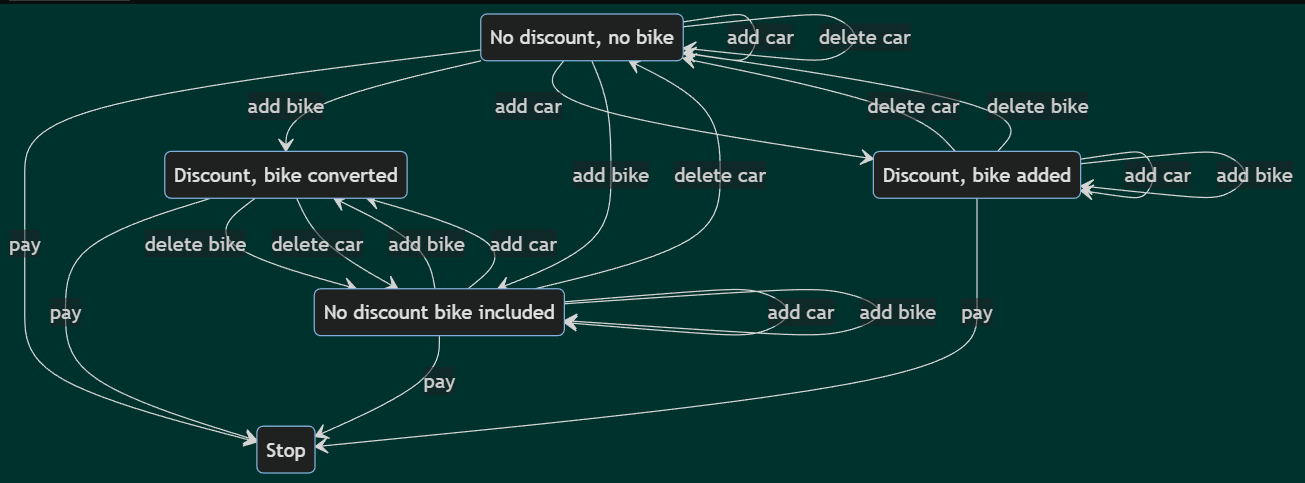
paths are generated. For example, from the starting point, traversing add bike to go to state Discount, bike converted is invalid as before ‘add car’ should be traversed twice. Thus, guard conditions are required.
For example, the guard condition for the add car transition starting and going back to the No discount, no bike state is:
total price < 400.
However, the total price is output, thus you should code it according to the requirements.
What has happened? You modeled an application that computes the total price of items in the cart. However, while making the model you should code the total price that is the task of the implementation. It’s obvious that you can make mistakes while making this code and the tests may become wrong. It’s a simple example, and there are cases when coding the output can be more difficult. When there are many transitions, adding the necessary guard conditions is time-consuming and error-prone.
If the guard conditions contain only inputs, then the graph will not contain the output values as in a state it can be different according to the path traversed. When the tests are generated, you should add the correct outputs for each test case.
Another problem is that when there are no inner states in the system, how can the states be handled? It’s not easy as you should ad-hoc cut the states not knowing whether the tests based on the reduced graph remain reliable. I think in this case the stateless solution is simpler and leads to the same result considering defect detection.
That may be the main reason why state transition testing is not widely used among testers and much fewer tools implementing it exists. Such tools are Opkey and Conformiq Creator.
Conclusion
We reviewed two classes of model-based testing. The simplest and most widely used technique is the stateless solution. These tools can be generally applied and easy to use, but there are two shortcomings:
- they require constraints/coding;
- they detect only simple bugs for complex systems including inner states.
The state-transition testing method is more difficult to use but more reliable, i.e., it can detect tricky bugs for more complex systems. These methods also have two shortcomings:
- they require coding, sometimes the expected output should be coded;
- for less complex systems, determining the necessary states is difficult, and so is the state transition graph
An obvious question is which one should I select. The answer is neither of them. The third class, ‘aggregate’ is better. A specific MBT method referred to as action-state testing addresses all the issues of these methods. In my next blog, I will show this technique and its usage.


Author’s Profile
Istvan Forgacs
István Forgács PhD is an entrepreneur, a test expert and an author. He is the lead author of the book Practical Test Design and Paradigm Shift in Software Testing and the co-author of the Agile Testing Foundations. He is the creator and key contributor of the test-first, codeless test design automation tool Harmony. With his co-author Prof. Attila Kovács, they created a website that is a unique place where testers can exercise test design by executing and improving their tests. They introduced three test design techniques: combinative testing, action-state testing and general predicate testing.
Blogs: 8
Got Questions? Drop them on LambdaTest Community. Visit now












