
Efficient Test Design – The Why, Which, and How ?
Istvan Forgacs
Posted On: July 29, 2022
![]() 12618 Views
12618 Views
![]() 11 Min Read
11 Min Read
Why good test design is inevitable?
Many books, blog posts, etc. state that either you spend lots of money and time for testing to reach high quality or you save money but your software quality remains poor. It’s not true. The reality is that there are two significant cost elements in the software development lifecycle (SDLC) that the teams can modify: testing and bug fixing. Neither of them is linear.
The cost of testing increases when we want to find more bugs. In the very beginning, the increase is more or less linear, i.e., executing twice as many test cases mean the number of detected bugs will be doubled. However, by adding more test cases the cost becomes non-linear. The reason is that after a certain level we need to combine (and test) the elements of the input domain by combinatorial methods. For example, we first test some partitions, then their boundaries, then pairs or triples of boundary values, etc. Suppose that the number of test cases is not negligible in the project. There is no reason to design and execute too many tests since we are unable to find a significant number of bugs even with many additional tests.
The other factor is the cost of defect correction (bug fixing). The later we find a bug in the software lifecycle, the more costly its correction. According to some publications, the correction cost is “exponential in time” but clearly over linear, most likely showing polynomial growth. Therefore, if we can find faults early enough in the lifecycle, then the total correcting costs can drastically be reduced. As you can see below, considering these two factors together, the total cost has an optimum value. (The figures are not real, only demonstrate the concept)
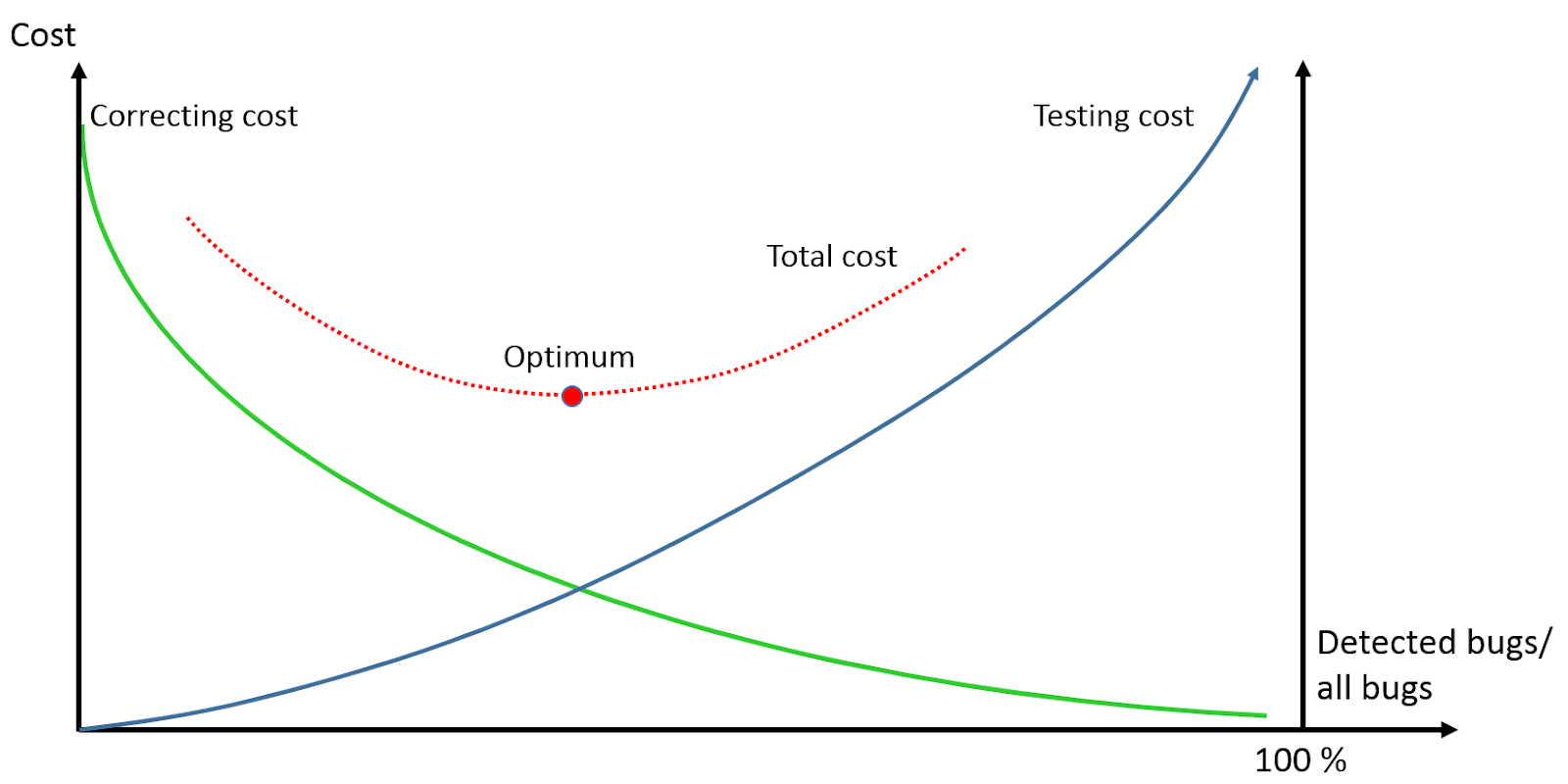
This means that it’s not a good strategy to reduce testing and testing costs as you should consider these two factors together. The main question is — does this cost optimum result in an acceptable production code quality? This is not a simple question. Assume that you apply an inefficient test design. In this case, with a high testing cost, the number of undetected bugs remains high and even if you reach the optimum, the software quality may not be acceptable. On the contrary, if you apply very efficient test design techniques, the optimum will be moved to a point where the detected bug ratio is much higher resulting in an acceptable quality, see the figure below:
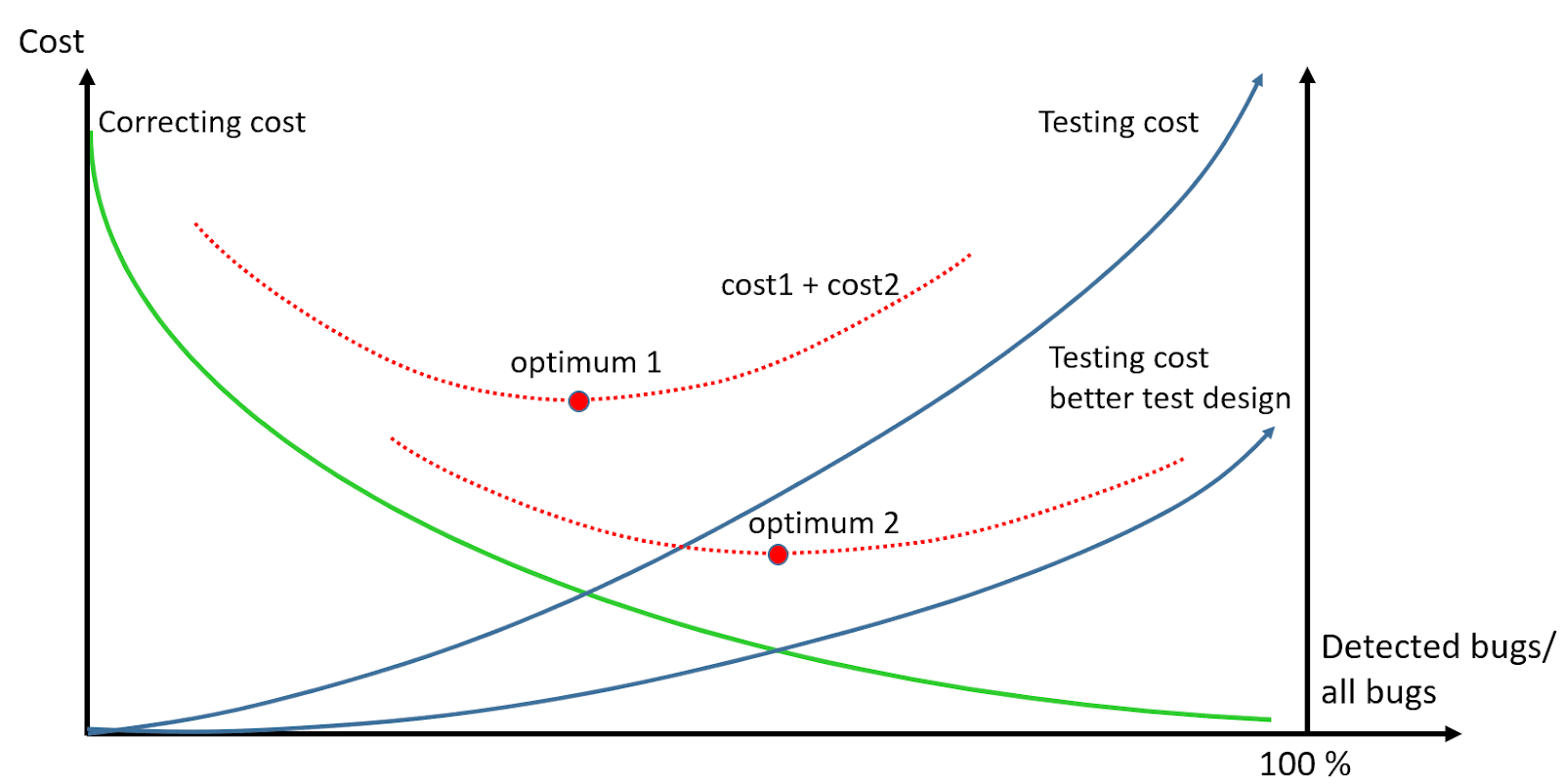
Thus, an efficient test design technique is necessary for the SDLC cost to decrease and the code quality to become acceptable at the same time. However different features require a different level of test design. Let’s consider two implemented features, and assume that the code of the first one is more complex (in some aspects). Hence, it contains faults with a higher probability. If we test both at the same expense and thoroughness, then after testing, more faults will be left in the first code. It means that the total correcting cost will be higher.
We can use similar arguments for considering risk. Suppose that we have two features having the same complexity and testing cost (the distribution of faults is similar), but the first one is riskier. For example, this feature is used more often, or the feature is used in a “critical” flow. Therefore, more bugs will be detected and fixed in this function with a higher correcting cost during the lifecycle. Note that we are speaking about the detection of bugs here, not about the presence of bugs.
Roughly speaking, more complex code and higher risk raise the bug-fixing costs if the testing effort/cost remains unchanged. Since this additional bug fixing occurs later in the lifecycle, the code quality at release will be poorer. Therefore, a riskier or more complex feature must be tested with more thoroughness, i.e., with higher testing costs. This higher testing cost is inevitable to achieve the optimal total cost, see this figure below, where HRF is a high-risk function and LRF is a low-risk function.
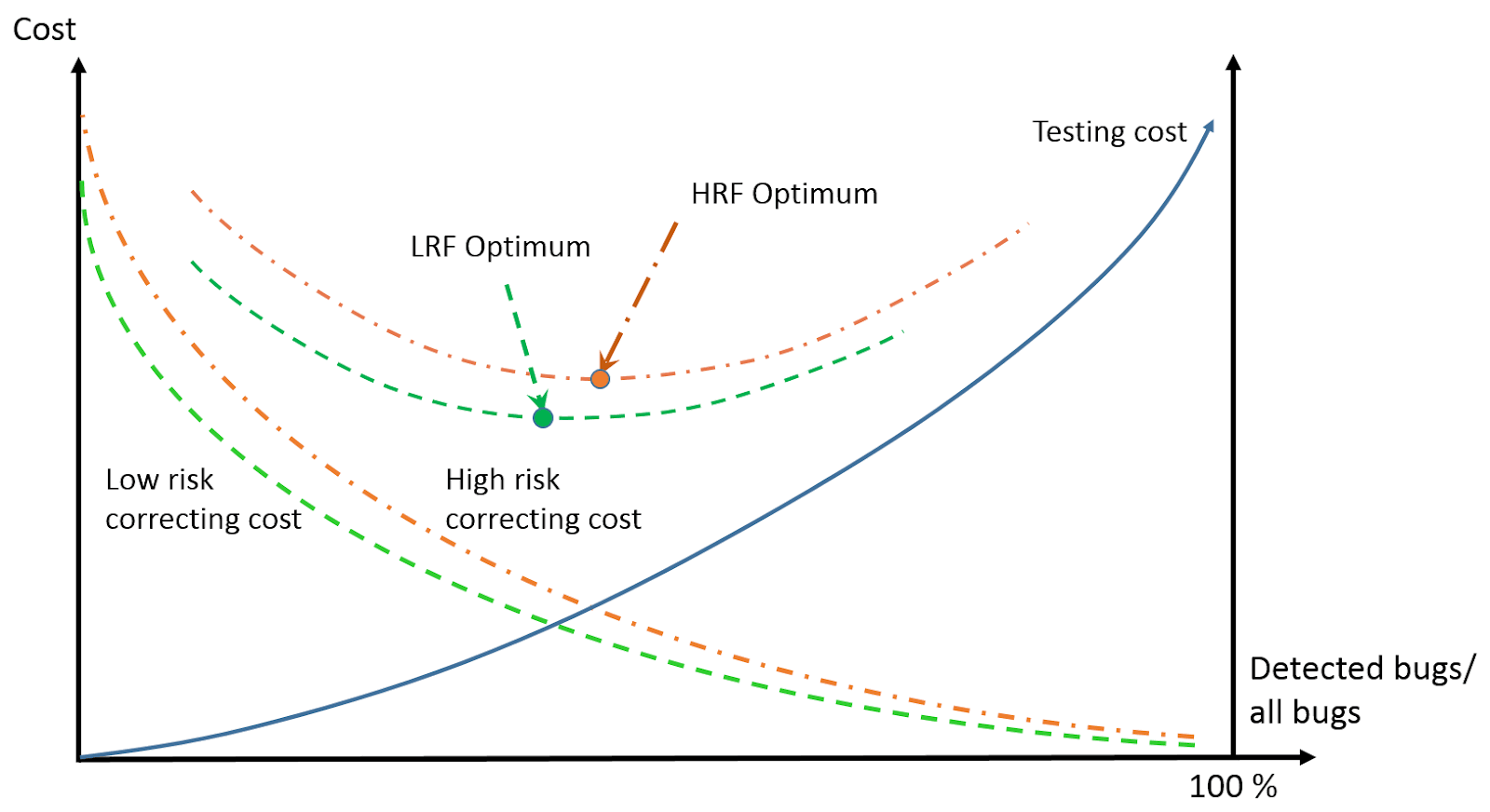
For traditional risk analysis, there are two factors, impact and probability. Here we can consider complexity as a third factor.
By mapping the size of the risk to the features, we can make the test design close to the optimum. For riskier code, we should select stronger test design techniques. A good option is to use the same test design technique with different test selection criteria. For example, if you use state transition testing or action-state test design technique you can select the minimum test selection criterion, all-transition testing for low-risk features, or riskier features a stronger all-transition pairs criterion. You can use even stronger criteria, if necessary.
Let’s assume that you do opt for stronger test design techniques for riskier features, but how can you check that you are close to the optimum? This is not an easy task. The only way is to collect as much data as you can. For example: let’s measure your testing effort for the features separately. Apply a simpler criterion first, then extend it and measure both efforts. Then measure the bugfix cost for the detected bugs. Finally, measure the bugfix cost for the bug detected after release. Now you can calculate the sum of testing and fixing costs for applying the weaker and the stronger criteria by approximating the bugfix cost for the simpler criterion (for the bugs detected by the stronger criterion). Finally, consider the risk. If the total cost for the simpler criterion is lower then you can select this criterion for that risk value. Using these data, you can select the appropriate test design level for a given risk.
Which tests should be automated?
Nobody automates all the test cases. Some features are not very important or the probability of changing the functionality is close to zero (assuming this feature is independent of the others in the static analysis sense). Test automation cost is significant with respect to single manual test execution. Is it reasonable to automate these features? Of course not. There may also be features that will be changed only once or twice. If test automation costs five times that of a single manual test then automation is worthless.
On the other hand, if a bug would block the use of the software or the feature will be modified several times or influenced by many frequently changed features, then test automation is a must, no doubt about it.
Again, we can do a risk analysis. If the impact is very high or high, then we should automate the test even if no change will occur. The reason is that even if a feature remains unchanged, some other features may influence it. If these ‘influencer’ features are changing, the unmodified may go wrong. The question is how to calculate risks. Obviously, the impact is a key factor. Probability is another to consider. However, instead of complexity, we should consider another type of probability, i.e., the probability of change.
Thus, risk analysis happens once and all the four risk items (impact, probability, complexity, and probability of change) should be determined by the team. You can use the well-known risk poker. According to the risks, you can decide which features to be automated. The risk analysis also helps if you want to make regression testing in different intensities. For example, you can execute some feature’s tests with high risk after each code modification and some others with lower risk just once a week.
The final step is the validation to improve the process. Here you can validate whether the automation of features was reasonable. You know the bugs detected during automated test execution, the bug fixing cost related to these bugs, you measure the test automation cost and you have historical data about the average bugfix cost of the bugs detected after release. Based on these data you can calculate whether automation was reasonable or not. If not, you can fine-tune your risk-based strategy.
How tests should be automated?
Excellent! We have a good test design and we know what to automate. The only thing to do is the test automation itself. At the first glance, tests are easy to automate. Test cases consist of user actions and system responses. In both cases, you should identify the UI object under test. For any test automation framework, the solution is similar. For actions, you use a selector/locator and a keyword. Here is an example using Cypress:
|
1 |
cy.get("#add Coke").click() |
Here #add Coke selects the ‘+’ button of adding a coke, and click() is the keyword to click on this button. For validation the solution is quite similar:
|
1 |
cy.get('#birthday').should('have.value', '11/01/1983') |
You can write the test code very fast, however, there is a significant problem: DRY, i.e., Don’t Repeat Yourself. DRY ‘is a principle of software development aimed at reducing repetition of software patterns’. As probably more test cases contain clicking on the add coke button, the same statement will be repeated. During maintenance, if the test is changing you should change it in many locations.
To avoid this, the page object model (POM) is suggested. The page object model is a design pattern where the page objects are separated from the automation test scripts. You should create separate classes for every page in the application. Then individual methods for each action and response are created and also the selectors are separated. For example, here is the POM version for adding coke:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
const addCokeSelector = "#add Coke"; class Example { addCoke() { cy.get(addCokeSelector).click(); } } it('add coke', () => { const example = new Example(); cy.visit('https://site_of_add_coke) example.addCoke(); }) |
Now if the selector or action code should be modified, you can do it at a single location. Very good, we are done. Oops, there is a problem: the POM code is much larger than the original. Instead of a single statement, there is a variable declaration for the selector, there is a method for the action/response and there is a call to the method. Roughly speaking we tripled the code size to keep DRY. However,
- some actions/responses are never modified.
- some actions/responses are in a single test case and only once. In this case, modification occurs just in a single location.
You may think that ‘no problem, let’s use risk analysis again’. Unfortunately, here we should analyze each action/response separately which is very costly. What can be done now? Fortunately, there is a good solution: model-based testing!
Model-based testing (MBT) is a technique that inherently involves DRY solution. The essence of MBT is that instead of creating test cases one by one manually, we create an appropriate test model from which an MBT tool can generate test cases based on the appropriate test selection criteria. The model can be textual or graphical. Models are based on test design techniques. For example, statecharts are the representations doing state transition testing. Here is the statechart of the well-known ATM authentication:
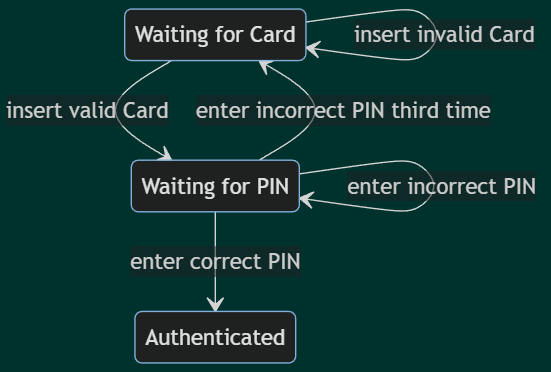
Satisfying the all-transition pair criterion, the action ‘insert valid Card’ is involved three times. In the model, this action occurs only once. This means that this action is implemented only once, and in case of any modification, you should modify it in a single location. Models are obviously more compact than the objects the models represent. My experience tells me that the textual model consists of a third of the simplest (non-POM) test code. Thus, the POM version is approximately nine times larger than the model. In another blog, I will compare the different MBT methods, but every method is better than using the original POM.
Another advantage of using MBT is that test design and test execution automation are merged. We informally proved that advanced test design is a must. Making a separate test design, then writing the tests one by one is entirely superfluous. Making a model and then generating the tests is a fast and efficient solution. Maintenance is also efficient as you never touch the code, only the model. The test code is generated after each model modification.
This means that using MBT and a test execution framework together is the best approach resulting in high software quality and lower SDLC cost.
Conclusion
There are many misconceptions about software testing. Here I showed that using an efficient test design doesn’t only lead to better quality but also decreases the total SDLC cost. I tried to answer the question of which test cases should be automated. Finally, I showed that using MBT makes test automation work more efficient. Don’t throw your test automation framework away, but extend it with test design automation tools. In another blog, I will show how to do it.
I hope I answered all the questions raised in the title.


Author’s Profile
Istvan Forgacs
István Forgács PhD is an entrepreneur, a test expert and an author. He is the lead author of the book Practical Test Design and Paradigm Shift in Software Testing and the co-author of the Agile Testing Foundations. He is the creator and key contributor of the test-first, codeless test design automation tool Harmony. With his co-author Prof. Attila Kovács, they created a website that is a unique place where testers can exercise test design by executing and improving their tests. They introduced three test design techniques: combinative testing, action-state testing and general predicate testing.
Blogs: 8
Got Questions? Drop them on LambdaTest Community. Visit now












