
Test Recommender Systems: Soumya Mukherjee [Testμ 2022]
LambdaTest
Posted On: August 30, 2022
![]() 6031 Views
6031 Views
![]() 8 Min Read
8 Min Read
As our regression pack grows, there has always been a case for shortening the testing cycle. To test the software application’s code effectively, it’s crucial to identify the tests that only affect the system due to specific build changes. However, achieving this task manually can be cumbersome since it requires knowing which tests are affected by the code changes.
This is where a test recommender system comes into play. It can quickly pinpoint which tests are affected by the code commit and then select them for targeted regression.
In this session of the Testμ Conference, Soumya Mukherjee, Engineer Manager at Apple, teamed up with Shantanu Wali – Product Manager at LambdaTest, to explain why a test recommendation system today is the need of the hour.
Soumya Mukherjee is an engineering manager at Apple. He comes with over 17 years of extensive experience in intelligent test automation with different tools and tech stacks, creating web products for QA, applying machine learning concepts in QA, and is passionate about devising solutions to complex problems in applied reliability engineering.
Other than that, Soumya has expertise in reducing an organization’s test cycle time via effective resource utilization. He has also authored books on Selenium for Tata McGraw-Hill and Amazon.
Soumya started the session by explaining different types of recommendation systems in the market, like item hierarchy-based systems, attribute-based systems, collaborative filtering, social interest-based graph system, knowledge-based system, and more. Major organizations and enterprises leverage these recommendation systems engines to get the users to buy their products.
Test prediction – how it was done?
We performed some test execution earlier, and the results are recorded in the database. Then fault tracking or failure probability on the data (test results) is done. After that, people would see how many executed test cases have failed versus how many times it has passed, and then they predict whether the team should run the test or not.

What is the problem with the above approach?
If you look at the tests that are getting flagged, you will notice that it will always flag your flaky tests; therefore, sometimes, few of the tests will pass, and few will fail. So it will always predict your flaky test and always flag a test with a high failure rate.
Also, there is no correlation or connection between your application code, which means when you are executing a set of tests each time and when it fails, you are flagging it, but if some code is changing, how can you relate that whether you should run that test or not or which are the right ones.
From the above discussion, Soumya highlights some of the classic challenges –
- Need to perform exhaustive testing for the change before merging to the main branch. It results in high test cycle time.
- Test-taking time in the pipeline affects engine productivity.
- QA engineers don’t have enough time to perform regression testing, and everyone wants their test to run faster.
Solution – Probabilistic model is the key
To identify which test to run from the regression pack for a specific code change, you can develop a probabilistic model. In a probabilistic model, you can hypothesize and perform a correlation between the parameters. There may be random parameters or may not so random parameters, or there may be completely random parameters.

We can then take the probability of my test failures and start correlating it with the code changes.
So the above probabilistic model was on the test side, but what if we want to connect it with the code?
Soumya further lists down three common approaches to achieve the same and standardize your data.
- Ingest historic execution data to a centralized location and perform correlation.
- Capture meta information of the test build having code change details and apply correlation with the unit test execution.
- Understand the probability of the tests that can fail due to specific codebase changes.
How to build a Model?
Saumya then went on to explain the model building. Basically, you can use a gradient-boosted decision tree model ( a standard machine learning algorithm) to build a model. A specific code change will identify all the impacted tests and determine the likelihood of failure.
But before doing this, you need to use code coverage tools and start instrumenting your code because you require some probing tools to give that code coverage whenever you run your tests. Post that, you can start doing the correlation with the gradient-boosted decision tree model.
Below is the screenshot of what your model would like.
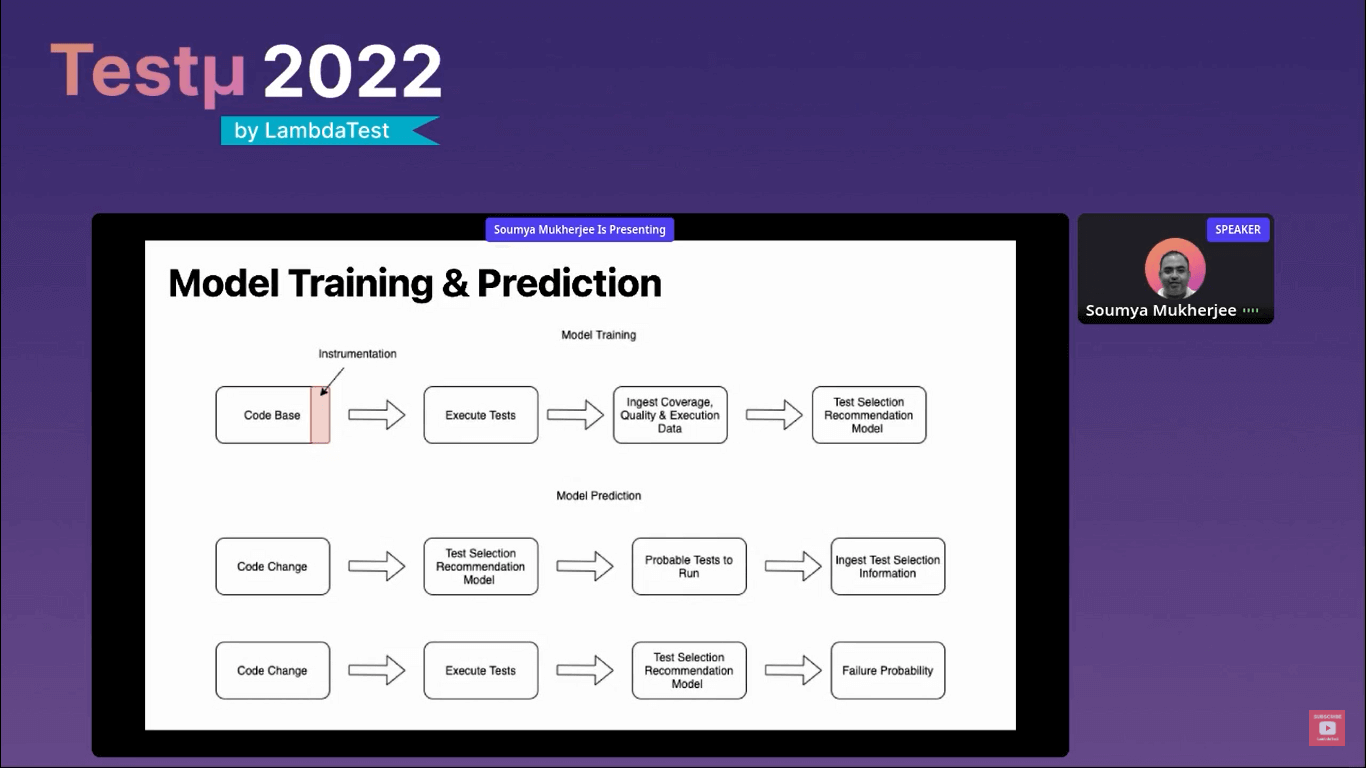
Model training and prediction
You have a codebase, you instrument your code (instrumentation is something like adding probes in your code), you execute your tests, ingest the coverage data, quality data, and execution data into the database, and then you run the gradient boosting model on top of that data.
Now you have the standardized data, code coverage versus the test that you have executed, and create the model. Once you do the model training, you can start making the prediction, do the code change, and run the model, and it will tell you the probability of your test failure. After that, you start ingesting your test selection information again.
When we feed this information back to the model and do the code change, execute your test and run the model, it will give you the failure probability of those tests. So this is the entire process of how you do model training and prediction.
You can use code coverage tools for code instrumentation: OpenClover, JaCoCo, Cypress, WebdriverIO, etc.
It’s time for a Q&A round!
There were some exciting questions poured in from the audience’s side. Let’s have a look at them.
- Which should we focus more on, picking up tools or picking up test automation frameworks?
- Can we use Allure History Trends Lines or Prometheus/Grafana to gather the data from our test runs?
- How do biases affect such models?
- Which tool do you recommend for automating recommendation systems with a lot of data and asserts that the results are expected ones? Did I have to populate the test data, take screenshots, and have historical data to compare each run?
Soumya: It is agnostic of tools and frameworks. So you need to ensure whichever tool or framework you are using, there should be a standard format for the output of a run. For instance, if you run hundreds of tests, it should split out the results in a standardized format.
Soumya: Allure or other reporting tools need an underlying JSON to create their reports. They generate that JSON object and then feed it to a service to create reports. So, you can pick up that JSON object, standardize it, then push it to your backend and start ingesting. In this way, your custom or extended report data can be pushed into your backend and do further analysis.
Soumya: Your model cannot be so close to your expectation. It has to be that there are biases that will affect your model when you start running the model and analyze how it behaves. The next problem that affects your system or model is refreshing your production data in the lower environments.
Therefore, each time you refresh production data in your lower environments and run something, you would notice that there is a failure. Your data is constantly changing, and it will add more and more bias. So you need to create the model in such a way that it keeps on learning from it.
Soumya: I think of this as a black box and start testing your system. For example, you know the input and output, and there has to be an expected result in testing.
You know the expected outcome, and the recommendation system will always give you the value in the range, so what you do is you keep pushing the inputs. Whatever output you expect has to be in the range so that it would be treated as a black box to start with your basic testing.
Yes, you have to populate the test data. You can check the precision of the model’s recall value to understand how your model behaves right when you keep pushing on the data.
After successful Testμ Conference 2022, where thousands of testers, QA professionals, developers worldwide join together to discuss on future of testing.
Join the testing revolution at LambdaTest Testμ Conference 2023. Register now!” – The testing revolution is happening, and you don’t want to be left behind. Join us at LambdaTest Testμ Conference 2023 and learn how to stay ahead of the curve. Register now and be a part of the revolution.


Author’s Profile
LambdaTest
LambdaTest is a continuous quality testing cloud platform that helps developers and testers ship code faster.
Blogs: 152
Got Questions? Drop them on LambdaTest Community. Visit now












