
Workshop on Test Intelligence: Anmol Gupta [Testμ 2022]
LambdaTest
Posted On: August 30, 2022
![]() 6237 Views
6237 Views
![]() 9 Min Read
9 Min Read
Teams’ testing requirements change as they expand. Running all of the tests gets challenging when test durations are lengthy. As a result, the teams waste a lot of time waiting to complete their test runs.
But that’s only the very beginning. It becomes challenging to distinguish between failures brought on by these faulty tests and actual faults when they are introduced into the system.
Anmol Gupta, Senior Product Manager at LambdaTest, conducted a workshop on Test Intelligence, and we were anxious to hear what he had to say. In this workshop, we will learn about the problems in detail and how to resolve them.
If you missed this session, here is the video link.
Here is the agenda of the session:
- Continuous Testing
- Problem at Scale
- What are Flaky Tests?
- Test Analytics
“Everyone wants to ship code fast.” Anmol started his talk by explaining the goal of doing DevOps. The code, features, and bugs are fixed at the fastest speed possible to go from the planning stage to the deploying stage.
But how to ensure that there are zero production defects? One must ensure that whatever they are making, merging, releasing, and deploying is tested at all possible stages. And that is what essentially continuous testing means. But what is required for continuous testing?

A large number of test cases are required to run continuous test cases. Anmol explains it with the ideal Testing Pyramid. We should have a good number of Unit Tests, followed by Integration Tests, API tests, and UI testing. Then manual exploratory testing follows.
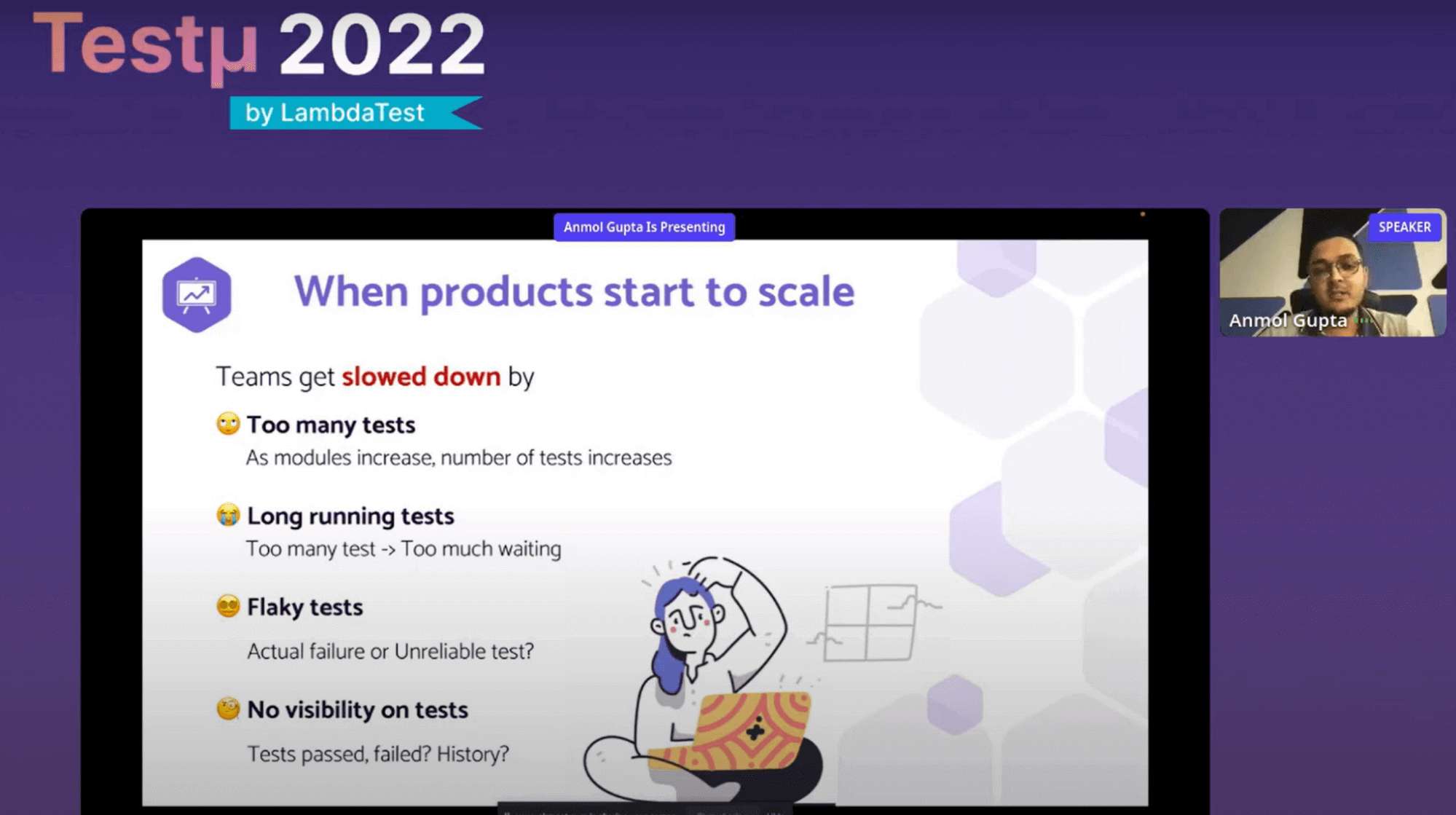
Teams frequently start with a large amount of manual testing, UI testing, followed by integration tests, and a dearth of unit test cases. Consequently, it is known as an inverted testing pyramid. But as products gain popularity, teams are slowed down for various reasons. The number of test cases starts to rise as the product undergoes more and more test cases.
Simply put, having too many test cases means you would have to wait an excessive amount of time for them to run and complete. Was it merely an unstable test case, or were flaky test cases a failure? The test cases cannot be seen, which is the last but not least issue.
The conventional CI/CD platforms provide the information that certain test cases passed and certain cases failed. But what about test case history? What about how a test case has behaved throughout numerous recent executions? But in terms of day-to-day operations, what does this entail? Anmol explains it clearly.

He discussed much too many test cases. It simply means that the release cycles’ test execution times are longer. Long-running test cases indicate that development teams are leaking a significant amount of velocity. Flaky test cases make it difficult for your development teams to do quality control checks and occasionally erode their trust in the test cases themselves. And because your test case is so lengthy, your continuous integration pipelines are just blocked from functioning.
Finally, it is exceedingly challenging for any team to calculate the ROI for your test cases because you have no visibility into them. He firmly believes that you cannot improve something if it is not being tracked or measured.
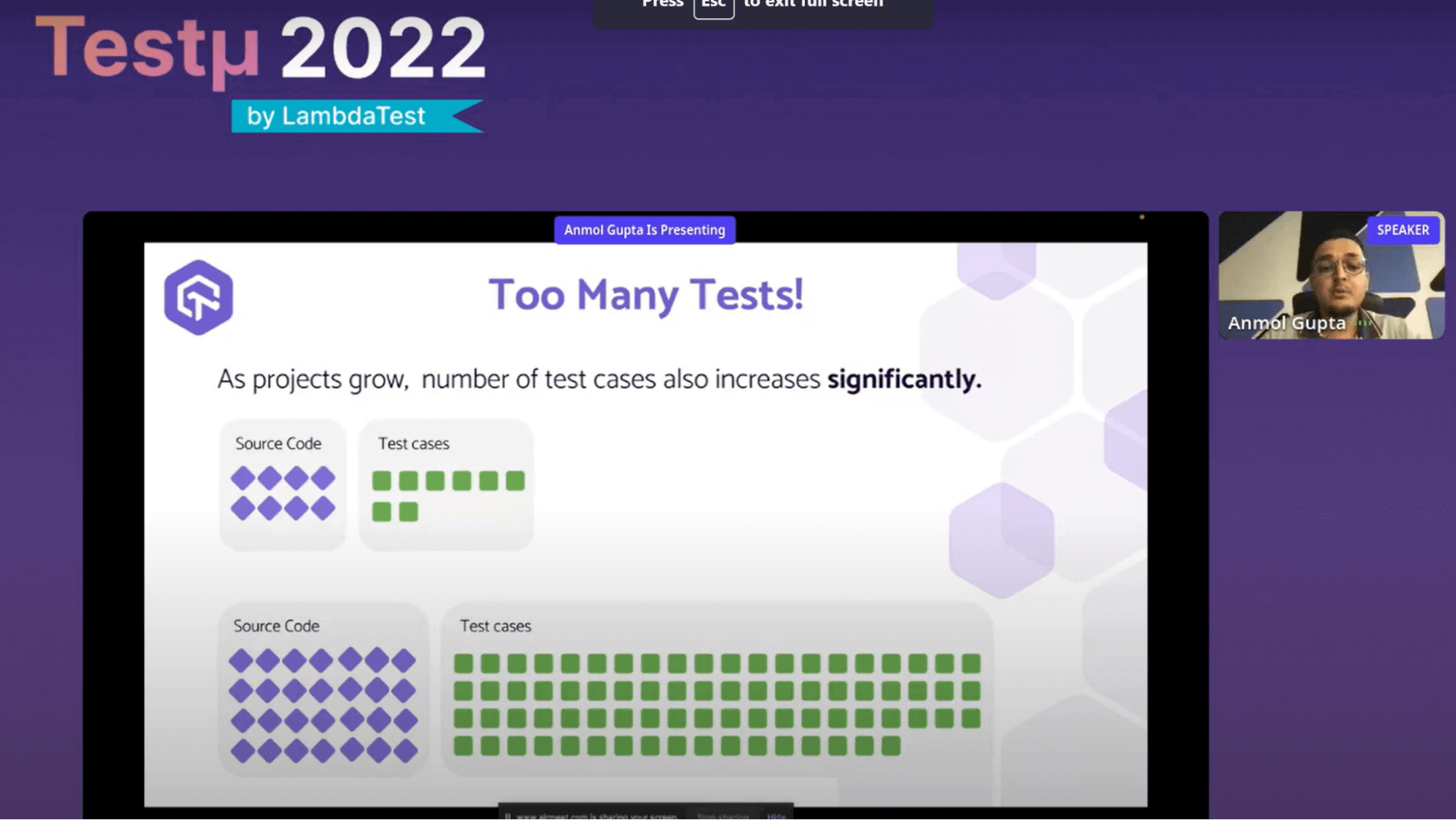
He discussed the first issue. With too many test cases, as a project expands, so do the number of test cases that go with it. But when that occurs, we all agree that the only viable option is to execute those test cases parallely. However, he explains what happens if we simply run those test cases concurrently. There are 45 test cases in his particular instance, each requiring a different amount of time to run. These test cases should be parallelized sequentially, considering five parallel nodes.
The test cases would essentially be parallelized in this way by the system. Is this accurate, you ask? “Absolutely not,” he says. Why? Because he just sequentially aligned these test cases, he discovered that the parallel nodes significantly differed. While the second node may take up to 23 minutes, the first node completes in just 9 minutes. And if you have a lot of test cases, this may go wrong. Therefore, smart parallelization is needed.

It is possible to organize and parallelize the same test scenarios intelligently. Thus, the test cases’ overall execution time and our nodes’ execution times are nearly identical, and he obtains results more quickly. Compared to his prior scenario, when the entire task took 23 minutes to complete, he now receives findings in 16 minutes. Thanks to the more intelligent orchestration processes.
Are our tests reliable?
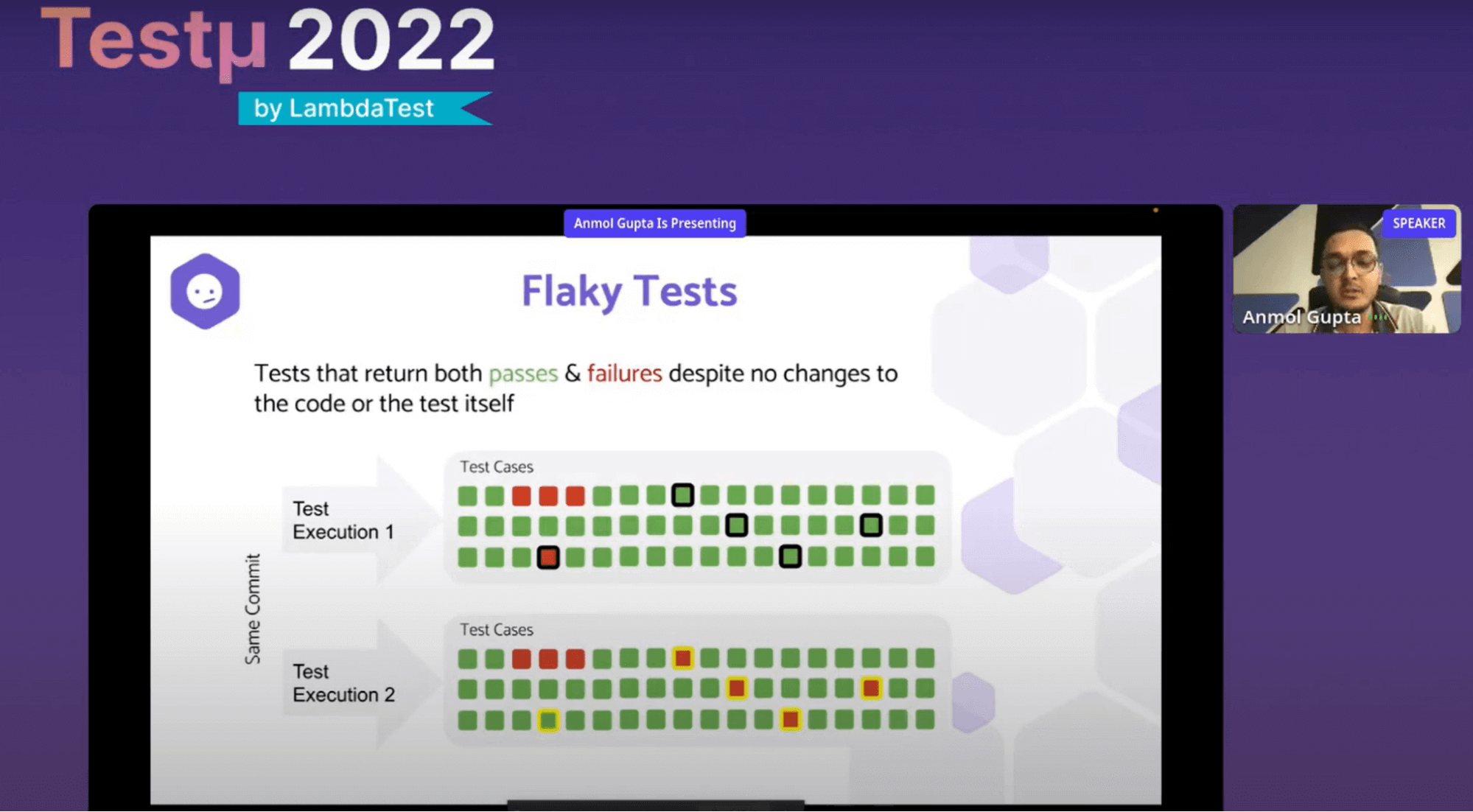
“Are our test cases reliable or not? How do we know that? asks Anmol. This brings up the subject of flaky tests. However, before he continued, he first defined a flaky test case. As we can see on the screen above, there has only been one commit, and the test cases have only been run twice. Some test cases fail the first time they are run, while others succeed. However, a new set of test cases failed during the second execution. Even though nothing changed in that commit, these five test cases yielded different outcomes for passing and failing. He refers to these as flaky test scenarios.
The issue extends beyond this. Because you have these flaky test cases in your system, it is confusing to your teams and chaotic for the development teams to determine if a failure or breakage occurred due to a code change that genuinely broke the build or resulted from a flaky test case. The dev teams would have spent countless hours determining the cause of a broken build, only to discover occasionally that the build failed due to a faulty test case that was added to the system perhaps a month earlier rather than a specific change in the code.
He explains multiple ways to combat flakiness:

He claims that there are more approaches to identifying and controlling proactive flakiness. “For example, what if he takes the test cases, rearranges the order of test cases, and then runs them several times to identify these flaky test cases? What if he lowers the standard of his testing environment to see what latency might be, at what specific computer, or what specific memory restrictions, and use that information to identify test cases that are unstable?
“To determine whether my test cases are testing my test code, how can I automate the mutation testing on my code? What is the level of my test case quality?” he asks. That ensures that the testing and the test are conducted.
Regarding the final issue, the modern CI/CD tools give us fundamental data. These are merely graphic representations of the test results or data. The only information we receive from the CICD standard tools is that these many test cases may pass while these many test cases may fail. A basic breakdown of how long or how my test cases are taking. Actionable insights are, however, lacking over there.
What exactly is needed? How can we debug more quickly? The time development teams spend transitioning from one location to another, moving from one gateway to another, and switching data sources can help you identify and resolve problems more quickly. We require intelligent reporting and analytics that give us practical knowledge that speeds up root cause analysis and shows us heat maps of our test cases.

Anmol finally wraps up the session with modern testing tools. Modern web applications need modern testing tools.
- Intelligent test orchestration techniques.
- Manage flaky tests proactively.
- In-depth, actionable insights.
It was indeed an insightful session with Anmol. The session ended with a few questions asked by the attendees to Anmol. Here is the Q&A:
- Is it true that a flaky test case can be managed with a stable environment? If so, how efficient is this?
- How do we avoid flaky test cases?
- Is there an intelligent extension for Azure DevOps?
Anmol: There are numerous reasons why a test case could be considered flaky when we talk about flaky test cases. It might help you a little if you ask, “Can we manage a flaky test case with a stable environment?” But certainly not over the long term. Why? Because if you look at it in this way, you have an environment that you may utilize for pre-production or a larger setting.
However, a test case could be unstable because it is unrelated to the environment; it could be calling an external API. And it could make your test case fail. It might succeed when it receives the response within that window, but it might also flop if there is network latency. Now, though you recently experienced a controlled atmosphere, it is not a guarantee.
Because it’s likely that in that environment, the network delays weren’t present, but when a client used that function and was utilizing it from a web app or their mobile device, they encountered a network delay. Check to see if your test case verifies that the feature has undergone the appropriate level of testing.
Anmol: You have at least seven to eight percent of test cases that are flaky, regardless of the type or size of your team. We don’t recognize that those test cases are flaky until after we’ve broken a build and realized that it wasn’t due to my changes but rather this test case. At that point, I truly realized that this was a flaky test case. In this manner, the flaky test case can be avoided.
Anmol: Yes, we are working on it at LambdaTest, and it will be out soon.
After the successfull Testμ Conference 2022, where thousands of testers, QA professionals, and developers worldwide joined together to discuss on future of testing.
Join the testing revolution at LambdaTest Testμ Conference 2023. Register now!” – The testing revolution is happening, and you don’t want to be left behind. Join us at LambdaTest Testμ Conference 2023 and learn how to stay ahead of the curve. Register now and be a part of the revolution.



Author’s Profile
LambdaTest
LambdaTest is a continuous quality testing cloud platform that helps developers and testers ship code faster.
Blogs: 175
Got Questions? Drop them on LambdaTest Community. Visit now













