
Page Object Model (POM) In Selenium Python
Himanshu Sheth
Posted On: March 11, 2021
![]() 117251 Views
117251 Views
![]() 18 Min Read
18 Min Read
This article is a part of our Content Hub. For more in-depth resources, check out our content hub on Selenium Python Tutorial.
Automation Testing is an integral part of the testing process. The primary objective of any type of testing process (automation or manual) is to improve the product quality by reporting bugs & getting them fixed by the development team. Irrespective of the software development model being followed in the project, increasing test automation coverage can be considered an important Key Performance Indicator (KPI) to measure the test code’s effectiveness.
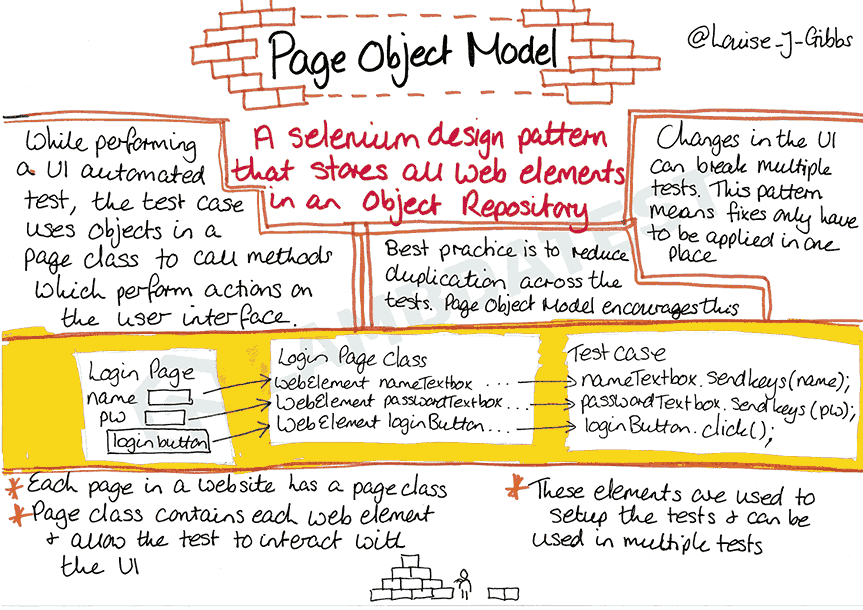
In this blog, we look at the Page Object Model (POM) in Selenium, a design pattern that helps create an object repository that stores all the web elements. POM reduces the maintenance effort by reducing the duplication of code. If you are preparing for an interview you can learn more through Selenium interview questions.
What Is Page Object Model?
Page Object Model (POM) is a design pattern in Selenium aimed at minimizing code duplication and streamlining code update and maintenance processes. Adopting POM allows you to create dedicated page classes for each webpage within your Automation Under Test (AUT).
POM provides an efficient object repository to store and manage web elements, facilitating enhanced test case management and reducing overall development effort.
This makes the code more modular since locators/elements used by the test suites/test scenarios are stored in a separate class file & the test cases (that contain the core test logic) are in a different file. Hence, any change in the web UI elements will require minimal (or no changes) in the test scenarios since locators & test scripts are stored separately.
Implementation based on the Page Object Model (POM) contains the below crucial elements:
- Page Object Element (Page Class/Page Object) – The Page Class is an object repository for the WebElements/Web UI Elements of the web-pages under test. It also contains an implementation of the interfaces/methods to perform operations on these web elements. It is loosely based on the fundamentals of Object-Oriented Programming.
- Test Cases – As the name suggests, test cases contain the implementation of the actual test scenarios. It uses page methods/methods in the page class to interact with the page’s UI elements. If there is a change in the UI of the web page, only the Page Class needs to be updated, and the test code remains unchanged.
There might be several Page Classes containing methods of different web pages in some complex test scenarios. It is recommended to follow a uniform naming nomenclature when choosing appropriate names of Page methods.
Why Use Page Object Model (POM)?
As a software project progresses, the complexity of the development code and the test code increases. Hence, a proper project structure must be followed when developing automation test code; else, the code might become unmanageable.
A web product (or project) consists of different web pages that use various WebElements (e.g., menu items, text boxes, checkboxes, radio buttons, etc.). The test cases will interact with these elements, and the code complexity will increase manifold if Selenium locators are not managed in the right way.
Duplication of source code or duplicated locators’ usage can make the code less readable, resulting in increased overhead costs for code maintenance. For example, your team needs to test the login functionality of an e-commerce website. Using Automation testing with Selenium, the test code can interact with the web page’s underlying UI or locators. What happens if the UI is revamped or the path of the elements on that page change? The automation test scenarios will fail as the scenarios would no longer find those locators on the web page.
Suppose you follow the same test development approach for more web-pages. In that case, a considerable effort has to be spent on updating the locators that might be scattered (or duplicated) across different files. This approach is also error-prone as developers need to find & update the path of the locators. In such scenarios, the Page Object Model can be advantageous as it offers the following:
- Eases the job of code maintainability
- Increases the readability and reusability quotient
Advantages Of Page Object Model
Now that you are aware of the basics of the Page Object Model, let’s have a look at some of the core advantages of using that design pattern:
- Increased Reusability – The page object methods in different POM classes can be reused across different test cases/test suites. Hence, the overall code size will reduce by a good margin due to the increase in the page methods’ reusability factor.
- Improved Maintainability – As the test scenarios and locators are stored separately, it makes the code cleaner, and less effort is spent on maintaining the test code.
- Minimal impact due to UI changes – Even if there are frequent changes in the UI, changes might only be required in the Object Repository (that stores the locators). There is minimal to no impact on the implementation of the test scenarios.
- Integration with multiple test frameworks – As the test implementation is separated from the repository of page objects (or page classes), we can use the same repository with different test frameworks. For example, Test Case – 1 can use the Robot framework, Tese Case – 2 can use the pytest framework, etc. single test suite can contain test cases implemented using different test frameworks.
This certification is for professionals looking to develop advanced, hands-on expertise in Selenium automation testing with Python and take their career to the next level.
Here’s a short glimpse of the Selenium Python 101 certification from LambdaTest:
Page Object Model In Selenium And Python
Developers and testers make extensive use of the Selenium Webdriver with programming languages like C#, Java, Python, JavaScript, PHP, and more. The advantage of using the Selenium Webdriver is developers can test their web-app or website on different types and versions of browsers, operating systems, and more.
Due to multi-platform support, Selenium is the most preferred framework as far as automation testing is concerned that’s why you should know What Is Selenium?
Page Object Model In Selenium And Python In Action (Example 1)
To demonstrate Page Object Model in Selenium and Python, we take the example of Google Search, where the search term is LambdaTest. We have used the PyCharm IDE (Community Edition), which can be downloaded from here for implementation. Below is the implementation with the unittest framework where the Selenium Webdriver instance is created to perform necessary interactions with the web browser.
For porting this implementation to the Page Object Model in Selenium & Python, we follow a directory structure that can be used irrespective of the scale & complexity of the project. The choice of directory structure depends on test requirements, the tests’ complexity, and prior development & test team experience.
Shown below is the directory structure that we used for the demonstration of the Page Object Model in Selenium & Python:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
Project-Directory |--------- Src |--------- PageObject |--------- Pages |--------- *Page.py (Implementation of methods that make use of the respective Locators declared in Locators.py) |--------- Locators.py |--------- TestBase |--------- WebDriverSetup.py |--------- Test |--------- Scripts |--------- test_*.py (Implementation of test code)(There should be 1:1 mapping of *Page.py and test_*.py as it helps in making the code more modular) |--------- TestSuite |--------- TestRunner.py (contains TestSuite, which is a collection of test cases) |
As shown in the above structure, the directory Project-Directory\PageObject contains Locators.py, where element locators are added depending on the requirements. Here is Locators.py for the Google search example:
FileName – Search\PageObject\Locators.py
Since the locators are added based on the web pages under test, any issue with the locators will require changes in the file that houses the locators (i.e., Locators.py) and no test code changes implementation. Below is the Page (HomePage.py) where the locators are used.
FileName – Search\PageObject\Pages\HomePage.py
Let’s do a code walkthrough:
We use the relative path to import modules or classes which are located in a different directory. Hence, we first append the Python module path to the syspath using sys.path.append(sys. path[0] + “/….”).
Locators.py is in the directory Search\Src\PageObject and HomePage.py is in the directory Search\PageObject\Pages. To append the right path, you can use PyCharm IDE, where once you append the required levels (with respect to the directory structure), the class or module will get recognized. For example, below is the screenshot where an incorrect relative path is used for using the Locator class in HomePage.py.
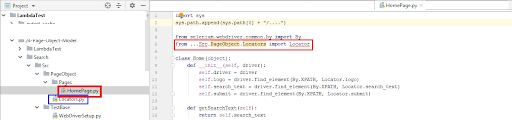
Since Locators.py is four levels up when we refer from HomePage.py 🡪 Src 🡪 PageObject 🡪 Pages, we append the same to syspath. The relative path changes at Line (5) are only for demonstration, and you can remove …. in the final implementation.
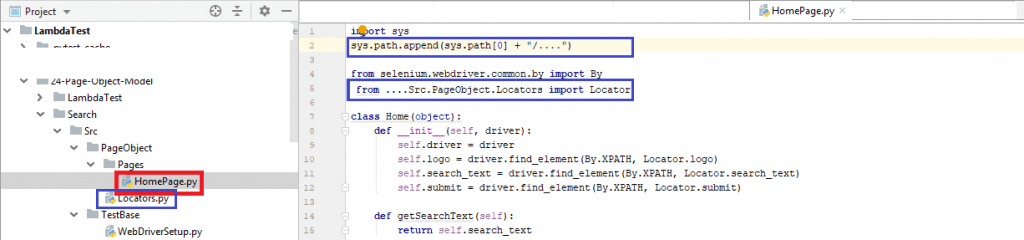
Initialization & setting up of the Selenium Webdriver is separated from the test suites and test scenarios for improving manageability and portability of the code. When you plan to perform automated browser testing using a remote web driver, change is only required in the WebDriver setup. The rest of the implementation remains unchanged! Shown below is the implementation of setup() & tearDown() methods of Selenium Webdriver.
FileName – Search\Src\TestBase\ WebDriverSetup.py
The intent of using the Page Object Model (POM) is to minimize the percentage of repetitive code and to make the code more portable by separating the implementation into the following sections:
- Locators, Pages (based on the web page under test)
- Test scripts (based on the web page under test)
- Test suites (aggregation of the test cases)
Now that the WebDriver Setup and implementation of required Pages are ready, we implement the corresponding test cases.
Below is the Search functionality implementation, which uses the test infrastructure (Locators + Pages), which we have completed so far.
FileName – Search\Test\Scripts\ test_Home_Page.py
FileName – Search\Test\Scripts\ test_Google_Search.py
To start with, an instance of the Home class is created so that the methods can be used in subsequent sections of the implementation. search_text.send_keys() and search_text.submit() methods are used to perform the search operation on the Google homepage. Here is the test suite implementation from where the respective tests are triggered:
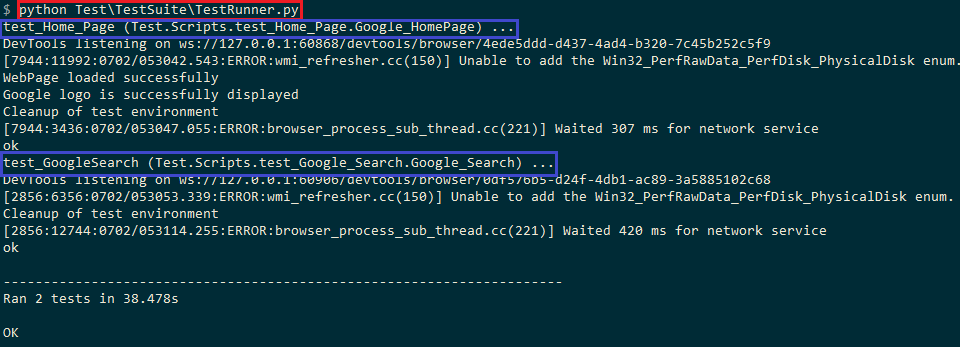
FileName – Search\Test\TestSuite\TestRunner.py
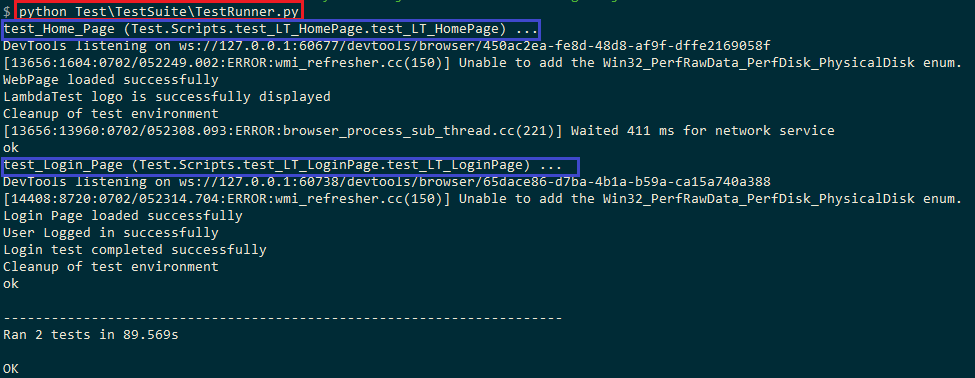
Below is the execution screenshot where the test suite is triggered from the terminal
Page Object Model In Selenium & Python In Action (Example 2)
We have a look at another example where the web page under test is LambdaTest. Below are the broad test requirements:
- Setup Selenium WebDriver for the Chrome web browser.
- Open the web page under test https://www.lambdatest.com.
- Locate the Login Button on the page and log in using the registered credentials.
- Check whether the login operation is successful and the LambdaTest Automation Dashboard is available.
- Perform a clean-up operation before exiting the test.
The directory structure used for the Google search example explained earlier is used for this test as well. You can use the Inspect tool available in Chrome/Firefox browser to find the locator information.
In this pyest Tutorial learn how to implement the Page Object Model design pattern in pytest and how to apply it while performing test automation.
Read More– Get started with your easy Selenium Python tutorial!!!
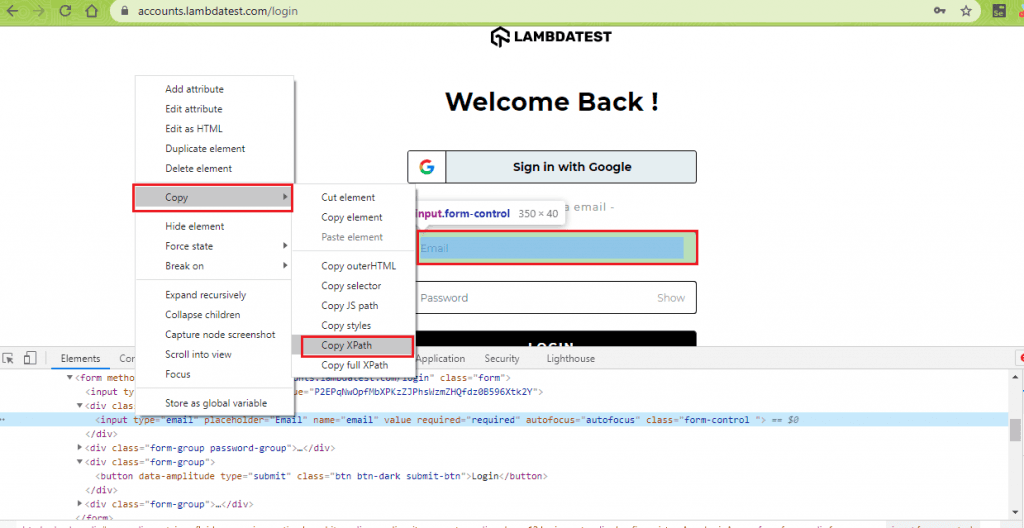
In the current test scenario, we need to find the locators for the LambdaTest homepage (https://www.lambdatest.com/) and the LambdaTest login page (https://accounts.lambdatest.com/login).
FileName – LambdaTest\PageObject\Locators.py
As there are two web pages to be tested, we create pages for HomePage and Login functionality. Below is the implementation of the LoginPage where necessary locators are used and required methods [e.g. get_LT_username(), get_LT_login_button(), etc.] to be used by the test case/test suites are implemented
FileName – LambdaTest\Src\PageObject\Pages\LT_LoginPage.py
Here is the implementation of the HomePage functionality:
FileName – LambdaTest\PageObject\Pages\LT_HomePage.py
On similar lines, we have a Page for testing the Home functionality of the LambdaTest website; hence we create LambdaTest\PageObject\Pages\LT_HomePage.py. With the declaration of the required locators (in Locators.py) and implementation of the HomePage and Login pages, we implement the Test equivalent of these Pages (i.e., test_LT_HomePage.py and test_LT_LoginPage.py)
Shown below is the implementation of the test case used to verify the Home functionality:
FileName – LambdaTest\Test\Scripts\test_LT_HomePage.py
Shown below is the implementation of the test case used to verify the Login functionality:
FileName – LambdaTest\Test\Scripts\test_LT_LoginPage.py
As seen from the implementation, initially, an instance of the Home class (LT_Home) is created. On successful creation, we make use of the lt_login.click() to navigate to the login screen.
Now that we are on a different web page i.e. https://accounts.lambdatest.com/login, an instance of the Login class (LT_Login) is created. Its corresponding methods lt_login_user_name() & lt_login_password() are used with send_keys() to populate the username & password fields on the page.
Verification of whether the login is successful is done by comparing the page title (of the page being displayed) with the intended page title. If the page titles match, the login is successful, and cleanup activities are performed. The two test cases are initiated from a test suite; implementation is shown below
FileName – LambdaTest\Test\TestSuite\TestRunner.py
For more information about the test case and test suite implementation using the Unittest framework, please refer to our earlier blogs, where these topics are discussed in more detail. Shown below is the execution screenshot of the tests performed on the URL under test, i.e., LambdaTest.
Automated Cross Browser Testing Using Page Object Model
The Page Object Model is a very useful design pattern that helps you design & implement test code that is more maintainable with minimal/no code duplication. During the course of web app testing, there might be frequent changes in UI and separating locators in the test code from the core implementation improves the modularity of the test code.
However, verification on different versions/types of browsers, operating systems, and devices can be a daunting task if the testing is performed in a local environment. Having a local setup for cross browser testing is neither scalable nor maintainable.
Hence, you should migrate your tests to a cloud-based cross browser testing platform where you can perform tests on different combinations of browsers, operating systems, and devices without housing them locally. Automated cross browser testing platform like LambdaTest lets you perform automated and live Interactive cross browser testing on 3000+ real browsers and Operating Systems online. There are minimal changes required in porting the test code from Local Selenium Webdriver to Remote Selenium Webdriver setup. The platform also lets you perform Parallel testing, resulting in a significant reduction in terms of effort & time spent on the automated cross browser testing.
To get started, you need to make an account on LambdaTest. Once you log in, you can access the LambdaTest Automation Dashboard, which shows the cross browser tests you have performed on LambdaTest. You can also perform Visual UI testing, Real-Time Testing (which requires no test implementation), and raise bugs through one-click bug logging by integrating with Jira, Asana, Slack, Bitbucket, Teamwork, Microsoft teams, or other issue tracking products.
To see automated cross browser testing on LambdaTest in action, let’s port the LambdaTest login test code. Changes in the setUp() method (located in WebDriverSetup.py) are done to perform testing on the LambdaTest platform. Login on LambdaTest platform is done using the username and passkey, which can be obtained from https://accounts.lambdatest.com/profile. Desired browser capabilities are passed to the remote Selenium web driver interface to set up the browser environment. You can also generate the desired capabilities from the Desired Capability Generator. Shown below are the changes that we did for performing automated cross browser testing on LambdaTest.
FileName –
You should execute the test suite from the terminal as you did for the earlier tests. To check the test status, you need to visit the Automation tab located in the LambdaTest Dashboard and click on the test that matches the build name you mentioned in the setup, i.e., Page Object Model Lambdatest using Unittest in our case.
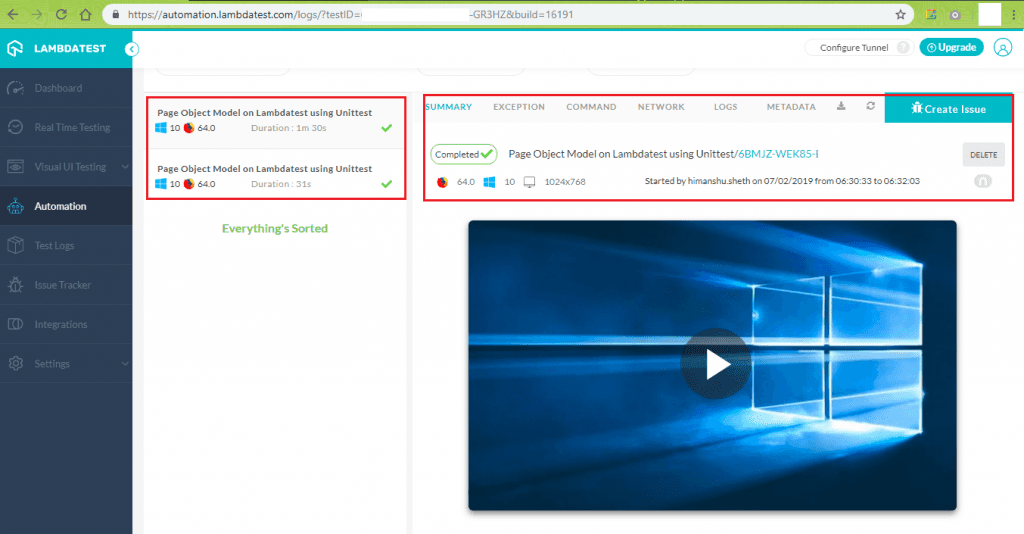
Hence, performing automated cross browser testing on a cloud-based platform like LambdaTest can be beneficial irrespective of the scale and complexity of the project/product.
Conclusion
Page Object Model can be used to make the test code more maintainable and minimize the amount of code duplication in your project/product. Though it helps make the code more modular, its overall impact can be more if used in conjunction with an automated cross browser testing platform.
The page object model in Selenium & Python is widely popular, and porting test code with local Selenium Webdriver to remote Selenium Webdriver requires minimal implementation changes. Hence, the Page Object Model framework on Automation testing with Selenium should be explored by the test & development team irrespective of whether there are frequent UI changes in the web app/website.
Frequently Asked Questions (FAQs)
What is page object model testing?
Page Object Model (POM) testing is a design pattern in Selenium that allows for the creation of an object repository to store all web elements. It enhances maintainability and reduces code duplication by keeping the methods and the locators separate from the test scripts.
What are the types of page object model?
The Page Object Model doesn’t technically have types, but it’s applied in different ways depending on the application’s complexity. You can have simple page objects with straightforward locators and methods, or complex page objects with nested page objects to mirror complex or multi-layered web applications.
What is Page Object Model vs Pagefactory?
Page Object Model and PageFactory are closely related, both being design patterns used in Selenium. While POM proposes a structure for organizing locators and methods, PageFactory is a class provided by Selenium WebDriver to support POM. PageFactory aids in initializing the elements of the Page Object or instantiates page objects itself.
How to write page object model in Selenium?
To write a Page Object Model in Selenium, you’d typically start by creating a class for each web page, identifying all relevant web elements on the page, and defining methods to interact with these elements. This encapsulates the page structure and offers reusable methods to interact with elements, separating the test logic from the UI interaction logic.


Author’s Profile
Himanshu Sheth
Himanshu Sheth is a seasoned technologist and blogger with more than 15+ years of diverse working experience. He currently works as the 'Lead Developer Evangelist' and 'Senior Manager [Technical Content Marketing]' at LambdaTest. He is very active with the startup community in Bengaluru (and down South) and loves interacting with passionate founders on his personal blog (which he has been maintaining since last 15+ years).
Blogs: 128
Got Questions? Drop them on LambdaTest Community. Visit now













