
Selenium C#: Page Object Model Tutorial With Examples
Himanshu Sheth
Posted On: April 24, 2020
![]() 142705 Views
142705 Views
![]() 16 Min Read
16 Min Read
This article is a part of our Content Hub. For more in-depth resources, check out our content hub on Selenium C# Tutorial.
While writing Selenium test automation scripts, it is important to make sure that your test scripts are scalable and can keep up with any changes in the UI of your web page. But, sadly it’s easier said than done! The goal of automated UI web tests is to verify the functionality of the elements of the web page. With the ever-changing UI, the web locators also change at times, these frequent changes in the web locators can make the task of code maintenance quite challenging.
I have come across many scenarios, where tests failed due to lack of proper maintenance. At times, a change in web locator, when the Selenium test automation scripts are not updated, can cause ‘most’ of the tests to fail!

The solution to this was simple, restructure the Selenium test automation scripts to make it more modular and minimize the duplication of code. So, how did I do it? I used a design pattern called the Page Object Model (POM), which helped in restructuring the code, thereby minimizing the overall effort spent in test code maintenance activity.
In this Selenium C# tutorial, I’ll give you a detailed look at Page Object Model along with how to implement it to make sure you maintain your Selenium test automation scripts in a better manner.
TABLE OF CONTENT
Page Object Model is language-agnostic, which means that the basic principles which we would discuss can be used for other programming languages like Python, Java, etc.
Why use Page Object Model in Selenium C#?
Selenium test automation scripts become more complex as the web applications add more features and web pages. With every new page added, new test scenarios are included in the Selenium test automation scripts. With this increase in LOC (Lines of Code), code maintenance can. become very tedious and time-consuming. Also, the Repetitive use of web locators and their respective test methods can make the test code difficult to read.
Instead of spending time updating the same set of locators in multiple Selenium test automation scripts, a design pattern such as the Page Object Model can be used for the development and maintenance of code.
In this Selenium C# tutorial, i’d implement Page Object Model is a widely used design pattern in Selenium that:
- Minimizes the usage of duplicated code.
- Makes the code more readable & maintainable as there is immense focus on aspects such as reusability, extensibility, etc.
What is Page Object Model (POM) In Selenium C#?
Page Object Model in Selenium C# is a design pattern that is extensively used by the Selenium community for automation tests. The basic design principle that the Page Object Model in Selenium C# follows is that a central object repository should be created for controls on a web page. Hence, each web page will be represented by a separate class.
The Page Objects (or page classes) contains the elements of the corresponding web page along with necessary methods to access the elements on the page. Hence, Selenium test automation implementation that uses the Page Object Model in Selenium C# will constitute different classes for each web page thereby making code maintenance easier.
For example, if automation for a login page & check-out page is to be performed, our implementation will have a class each for login & check-out. The controls for the login page are in the ‘login page’ class and controls for the check-out page are in the ‘check out page’ class.
The Selenium test automation scripts do not interact directly with web elements on the page, instead, a new layer (i.e. page class/page object) resides between the test code and UI on the web page.
In complex Selenium test automation scenarios, Selenium test automation scripts based on Page Object Model can have several page classes (or page objects). It is recommended that you follow a common nomenclature while coming up with file names (representing page objects) as well as the methods used in the corresponding classes.

RUN YOUR AUTOMATION SCRIPT ON SELENIUM GRID
3000+ Browsers AND OS
Advantages of Page Object Model In Selenium C#
Below are some of the major advantages of using the Page Object Model in Selenium C#
- Better Maintenance – With separate page objects (or page classes) for different web pages, functionality or web locator changes will have a less impact on the change in test scripts. This makes the code cleaner and more maintainable as Selenium test automation implementation is spread across separate page classes.
- Minimal Changes Due To UI Updates – The effect of changes in the web locators will only be limited to the page classes, created for automated browser testing of those web pages. This reduces the overall effort spent in changing test scripts due to frequent UI updates.
- Reusability – The page object methods defined in different page classes can be reused across Selenium test automation scripts. This, in turn, results in a reduction of code size as there is the increased usage of reusability with Page Object Model in Selenium C#.
Apart from these advantages of Page Object Model in Selenium C#, another plus point of using this design pattern I’d like to point out in this Selenium C# tutorial is that it simplifies the visualization of the functionality and model of the web page as both these entities are located in separate page classes.
Take this certification to master the fundamentals of Selenium automation testing with C# and prove your credibility as a tester.
Here’s a short glimpse of the Selenium C# 101 certification from LambdaTest:
What is Page Factory?
Page Factory, an extension to Page Objects, is primarily used for initialization of the web elements defined in the page classes (or page objects). Web elements used with Page Objects have to be initialized before they can be used further and Page Factory simplifies the initialization with the initElements method.
Shown below are some of the ways in which initElements function can be used:
Method 1
Method 2
Method 3
Using @FindsBy annotation, every WebElement variable is initialized by the Page Factory based on the locators configured to locate the element on the web page.
The @FindsBy annotation can accept XPath, Id, Name, CssSelector, ClassName, LinkText, PartialLinkText, etc. as attributes
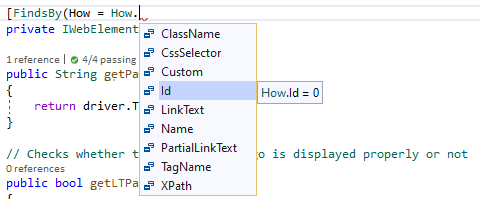
Each time a method is called on the WebElement variable, e.g. elem_search_text in the code snippet above for this Selenium C# tutorial, the Selenium WebDriver will find the element on the current web page before simulating the UI interaction.
The @CacheLookup annotation is used to cache the looked up field that was earlier read using the @FindsBy annotation. This annotation is very useful in scenarios where we know that the elements on the webpage can always be found, and we won’t be spending much time on that particular webpage, i.e. we would eventually navigate to a new page.
The @FindsBy annotation supports many other strategies; however, most of these strategies are not relevant in the context of cross browser testing or automated browser testing. More details about Page Factory are available on the official page of Page Factory.

How To Implement Page Object Model In Selenium C#
For Selenium test automation script development, we use the Visual Studio IDE (Community Edition) which can be downloaded from here. In case you want to know more about setting up selenium in visual studio, you can refer to our previous article on the topic.
To get started with this Selenium C# tutorial, you’ll have to create an account on LambdaTest and make a note of the user-name & access-key which is available on the Profile Page. We use the LambdaTest capabilities generator to generate Selenium capabilities for different browser + OS combinations.
Page Object Model – Directory Structure
Though the choice of the directory structure purely depends on the test requirements, it is important that a uniform structure is followed so that there are no ambiguities in development & enhancements.
We use the directory structure shown below for demonstrating the usage of the Page Object Model with C# and Selenium.

As shown in the structure above, the directory Project-Directory\Src\PageObject\Pages contains the Page Classes/Page Objects for the different web pages. The directory Project-Directory\Test\Scripts contains the actual test code implementation. The file(s) present in this directory will use the C# test framework (NUnit/xUnit/MSTest) for automated browser testing.
Page Object Model – Demonstration Using C#, Selenium, and NUnit Framework
We make use of the NUnit test framework in this Selenium C# tutorial for test case development. In case you want to know more about the NUnit test framework, you can take a look at our detailed article on NUnit test automation using Selenium C#.
To get started, create a new NUnit test Project in C# navigating to New -> Project -> NUnit Test Project (.Net Core).
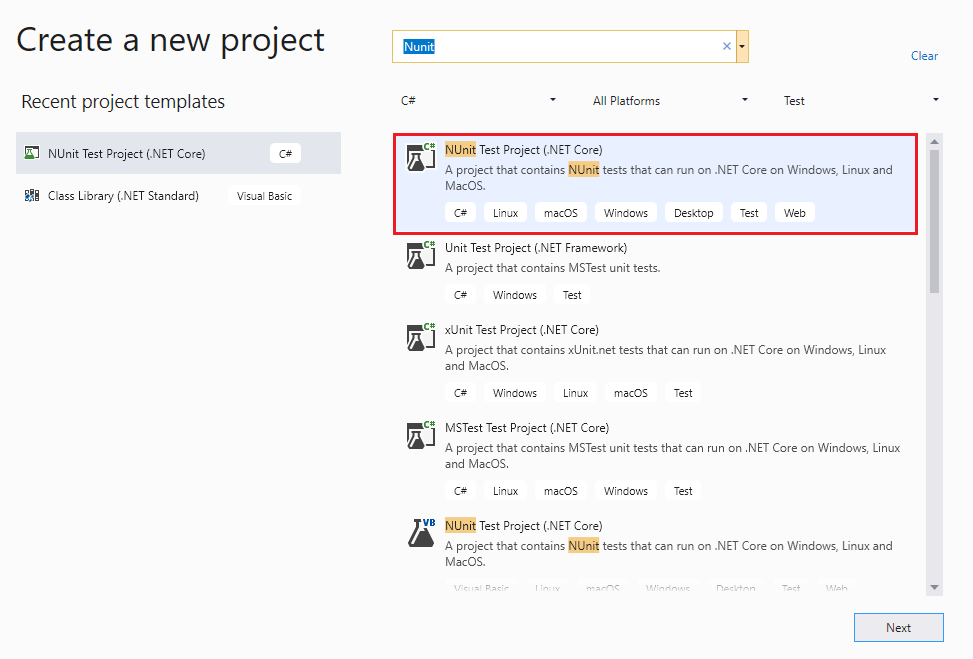
As the project is ready, you need to install the necessary packages for enabling support for Page Objects. Execute the following commands on the Page Manager (PM) console of the newly created project:
The status of the installed packages can be obtained using the Get-Package Package Manager command:
The PageFactory class is no longer a part of the Selenium.Support package. Instead, it is now a part of the DotNetSeleniumExtras Package, replacing the implementation originally supported by the Selenium project.
If you encounter the error “The name PageFactory does not exist in the current context”, make sure that DotNetSeleniumExtras package is installed & SeleniumExtras.PageObjects namespace is included in the code.
For demonstrating the usage of Page Object Model and Page Factory with Selenium & C#, let’s have a look at two test scenarios:
Test Scenario 1 – Google Search
In this example, I’ll search for ‘LambdaTest’ in the Google search bar. Here, we are running the test in parallel by using the Parallelizable attribute.
|
1 |
[Parallelizable(ParallelScope.All)] |
Below is the combination of browser + OS combinations on which cross browser testing is performed:
Implementation
For performing search on Google with search string as LambdaTest, we create three Page Classes/Page Objects as mentioned below:
HomePage.cs – This page class contains the locator information of the elements (required for cross browser testing) on the Google home page. Search for LambdaTest is also performed in this Page Object. The @FindsBy attribute is used on the properties in the HomePage Page Object to describe how the WebElements on the page can be found.
In the HomePage constructor, the page objects are initialized using the InitElements() method from the PageFactory class. In our case, the constructor of the page class i.e. HomePage which takes an input argument as a WebDriver instance is used.
Page objects with its fields initialized are returned on successful execution whereas an exception is thrown if the class cannot be instantiated.
The @FindsBy annotation is used to locate elements on the web page (google.com in this case). Though you can use the ‘Inspect’ option in Chrome/Firefox to locate the elements, we made use of the Selenium Page Object Generator extension in Chrome to for performing the job.
The test_search() method is created to perform a search for the desired input on Google. It returns the SearchPage object.
SearchPage.cs – This is the PageObject for the Google Search page. As the search results are already ready, a method for performing a click on the first test result is created as a part of this Page object.
The major part of the SearchPage page object implementation is self-explanatory as it is modelled on the design of HomePage page object. In the method click_search_results(), an async wait is implemented till the DOM status is Complete i.e. till the page load is complete. It returns the FinalPage page class.
FinalPage.cs – The Page Class that contains methods to check whether the intended page i.e. LambdaTest homepage has loaded or not.
As the destination web page i.e. LambdaTest home page is already loaded (via the click on the first search result on Google), an async wait is performed to ensure that the page load is complete.
Test Case Implementation (using NUnit framework)
Once the design of the Page Objects required for attaining the test scenario is complete, we implement the test code using the uses NUnit framework and Selenium test suite.
Browser capabilities for the browser + OS combinations are generated using the LambdaTest capabilities generator. The Selenium test automation cases are executed in parallel to leverage the capabilities of the LambdaTest platform. The option ParallelScope.All are used with the Parallelizable annotation so that the tests and its descendants can execute in parallel with others at the same level.
We make use of the appropriate methods in the HomePage, SearchPage, and FinalPage page objects to perform the Google search for LambdaTest.
The implementation is pretty straightforward and self-explanatory. The advantage of using Page Object Model in Selenium C# is evident from the test code as any changes in the UI will only affect that particular Page Object whereas the implementation in other Page Objects remains unchanged.
Shown below is the execution snapshot from LambdaTest dashboard and
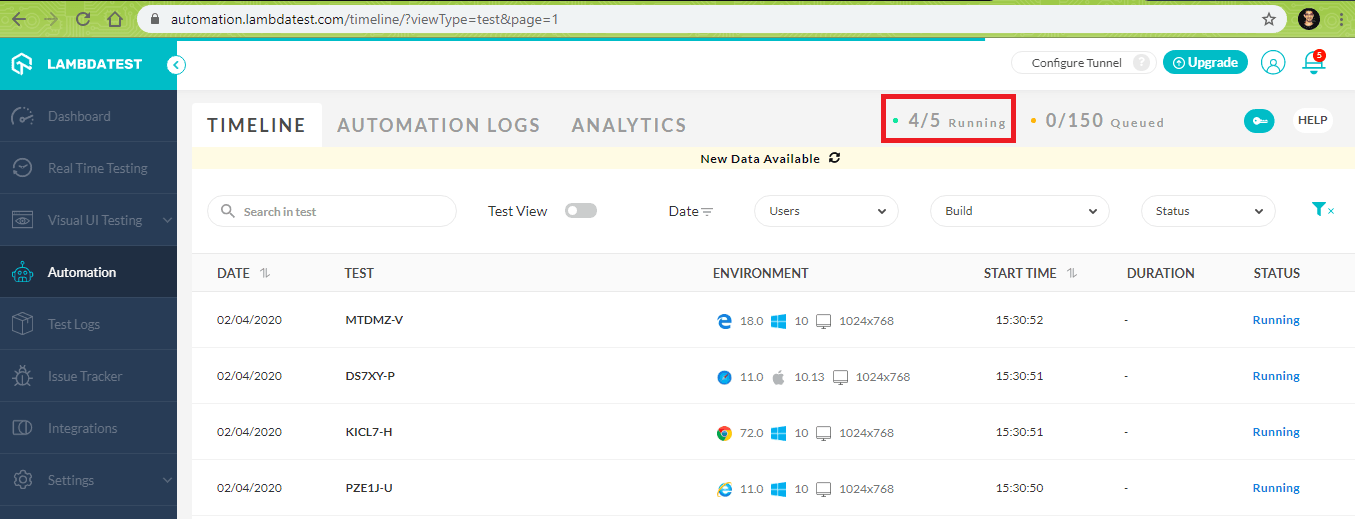
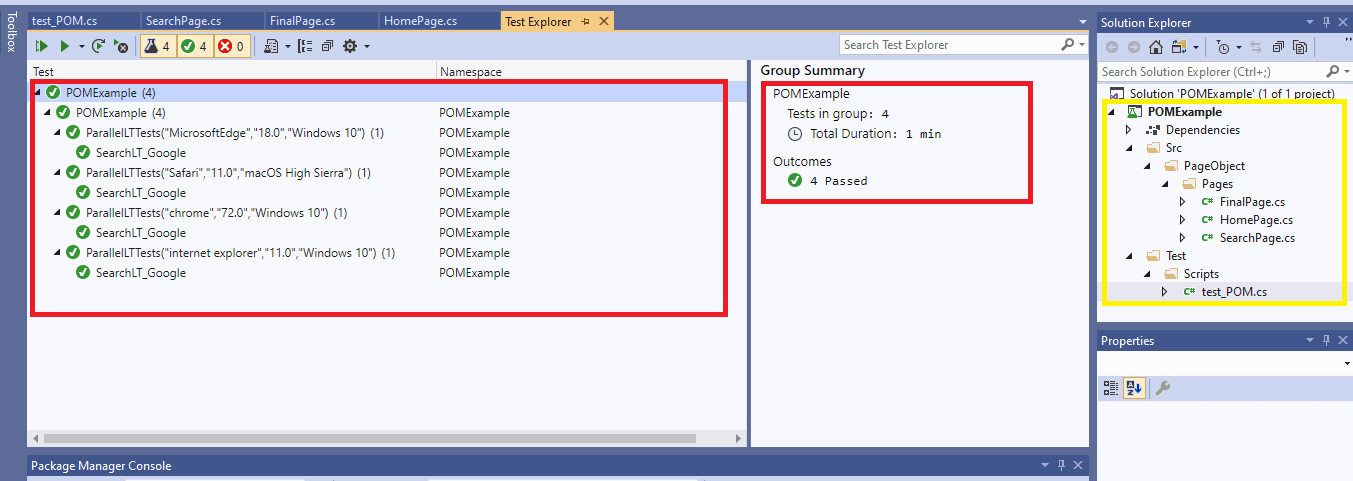
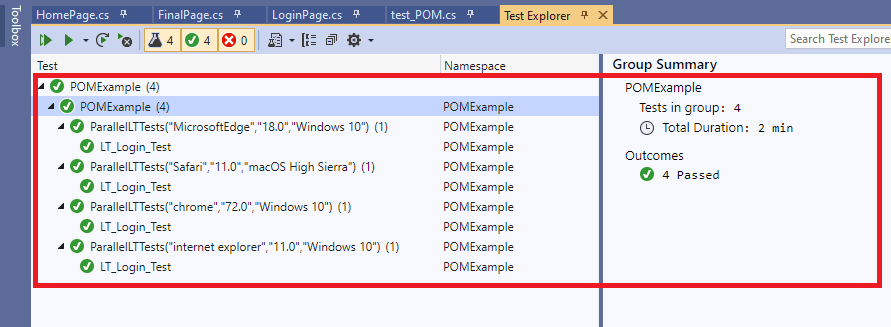
Execution snapshot from Visual Studio IDE.
Test Scenario 2 – Login on LambdaTest
For this Selenium C# tutorial for Page Object Model, let’s automate the Login process on LambdaTest. We have to automate the following steps
- Visit LambdaTest.com
- Click on ‘Sign In’ button
- Enter a valid combination of username and password
- Click on the ‘Login’ button
- Once on the automation dashboard, click on the Automation tab
The browser + OS combination remains the same as in the previous example.
Implementation
For automating the Login process on LambdaTest, we first breakdown the scenario in sub-scenarios and create a Page Object per sub-scenario. Below are the page objects/page classes created for automating the scenario:
HomePage.cs – This page class contains the locator information for the necessary web elements on the LambdaTest homepage. A method that returns LoginPage object is created. In the method, we locate the Login button and perform a click operation.
LoginPage.cs – This is the PageObject for the Login Page of Lambdatest i.e. https://accounts.lambdatest.com/login. In this Page Class, the username and password textboxes are located and a method that takes username & password as input arguments is created.
Once the ‘LOGIN’ button is clicked, we navigate to the Lambdatest dashboard. Hence, the method (submit_uidpwd) returns FinalPage page object.
FinalPage.cs – This is the PageObject for the LambdaTest Automation Dashboard. A method (automation_tab_click) is created to click on the Automation tab on the Dashboard. The rest of the implementation is self-explanatory.
Test Case Implementation (using NUnit framework)
Like the previous example, we implement a test case that uses the Page Objects and NUnit framework. As the same set of browser & OS combinations are used for testing, that part of the implementation remains unchanged.
In the code implemented under the [Test] annotation, the methods implemented by the Page Classes are used to automate the login operation on LambdaTest. The implementation is self-explanatory.
Shown below is the execution snapshot from LambdaTest
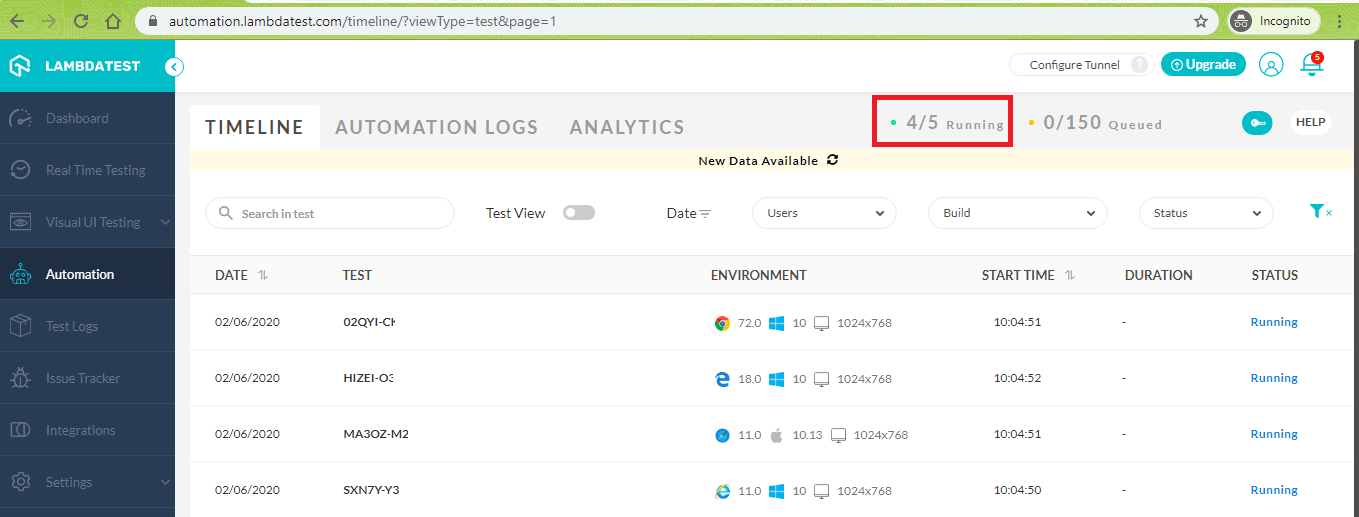
Execution Snapshot from Visual Studio IDE.
In order to scale your testing efforts, you’d need to use a Selenium Grid. You can do this in two ways by setting up a local Selenium grid or opting for a cloud based solution. The issue with using a local Selenium grid for Cross browser testing is that setting up a local infrastructure can be very tedious and time-consuming.
Instead, cloud-based cross browser testing on a remote Selenium grid can help in attaining better test coverage along with accelerated execution of the Selenium test automation scenarios. With LambdaTest Selenium Grid you can perform cross browser testing on 3000+ browsers & operating systems online. Parallel test execution on a remote Selenium grid can speed up the entire Selenium test automation process.
Wrapping It Up
In large consumer web applications, code maintenance can be a big challenge if corrective measures are not taken at the right time. With the Page Object Model in Selenium, you can improve the clarity and maintainability of the code. You no longer need to update each and every script just cause there is an update in the UI.

Page Object Model in Selenium C# is pivotal in automated browser testing as the testing can involve large numbers of browser & OS combinations. Irrespective of whether the product UI goes through frequent changes or not, it is always recommended to use a design pattern like Page Object Model that is programming language agnostic and extremely beneficial in the long run.
Update: We’ve now completed the Selenium C# tutorial series, so in order to help you easily navigate through the tutorials, we’ve compiled the complete list of tutorials, which you can find in the section below.
Selenium C# Tutorials With Examples
- Selenium C# Tutorial: Setting Up Selenium In Visual Studio
- Running First Selenium C# Script With NUnit
- Selenium C# Tutorial: Using Implicit Wait in Selenium
- Selenium C# Tutorial: Using Explicit and Fluent Wait in Selenium
- Selenium C# Tutorial: Handling Alert Windows
- Selenium C# Tutorial: Handling Multiple Browser Windows
- Selenium C# Tutorial: Handling Frames & iFrames With Examples
- Selenium C#: Page Object Model Tutorial With Examples
This brings us to the conclusion of the article and to our Selenium C# tutorial series, this was all I had to share on Page Object Model in Selenium C#. You now know how to keep up with those frequent UI changes, they won’t be a problem anymore. Help your peers, facing the same issue, retweet us and help us in reaching out to more people. Happy testing!!☺


Author’s Profile
Himanshu Sheth
Himanshu Sheth is a seasoned technologist and blogger with more than 15+ years of diverse working experience. He currently works as the 'Lead Developer Evangelist' and 'Senior Manager [Technical Content Marketing]' at LambdaTest. He is very active with the startup community in Bengaluru (and down South) and loves interacting with passionate founders on his personal blog (which he has been maintaining since last 15+ years).
Blogs: 128
Got Questions? Drop them on LambdaTest Community. Visit now













