
How To Perform Selenium and Python Web Scraping
Vinayak Sharma
Posted On: June 7, 2021
![]() 161547 Views
161547 Views
![]() 10 Min Read
10 Min Read
This article is a part of our Content Hub. For more in-depth resources, check out our content hub on Selenium Python Tutorial.
As per Stack Overflow Survey 2020, Python holds the fourth position in the preferred programming languages category. Moreover, it is supported across a wide range of test automation frameworks, including the Selenium framework. There selenium and Python Web Scraping is one of the most used combination for smarter data collection and intelligent analysis.
‘Data is the new oil,’ the ever-green quote by Humbly becomes much more relevant if the right methods are used for making the most out of the data. There is a plethora of information (read data) available on the internet, and acting on the right set of data can reap significant business benefits. Putting the right data collection methods in implementation can bring useful insights. On the other hand, incorrect data collection methods can result in obtuse data.
Web scraping, surveys, questionnaires, focus groups, oral histories, etc., are some of the widely used mechanisms for gathering data that matters! Out of all the data collection methods, web scraping is considered the most reliable and efficient data collection method. For starters, web scraping (also termed web data extraction) is an automatic method for scraping (or obtaining) large amounts of data from websites. Selenium, the popular test automation framework, can be extensively used for scraping web pages. You can also learn more about what is Selenium? In this Selenium Python tutorial, we look at web scraping using Selenium and Python.
We have chosen Python – the popular backend programming language for demonstrating web page scraping. Along with scraping information from static web pages, we will also look into web scraping of dynamic pages using python and selenium.
If you’re looking to improve your Selenium interview skills, check out our curated list of Selenium interview questions and answers.
TABLE OF CONTENT
What is Web Scraping
Web Scraping, also known as “Crawling” or “Spidering,” is a technique for web harvesting, which means collecting or extracting data from websites. Here, we use bots to extract content from HTML pages and store it in a database (or CSV file or some other file format). Scraper bot can be used to replicate entire website content, owing to which many varieties of digital businesses have been built around data harvesting and collection.
Python Web Scraping can help us extract an enormous volume of data about customers, products, people, stock markets, etc. The data has to be put to ‘optimal use’ for the betterment of the service. There is a debate whether web scraping is legal or not, the fact is that web scraping can be used for realizing legitimate use cases.
This certification is for professionals looking to develop advanced, hands-on expertise in Selenium automation testing with Python and take their career to the next level.
Here’s a short glimpse of the Selenium Python 101 certification from LambdaTest:
Use Cases for Python Web Scraping
Here are some of the valid (or authorized) use cases of web scraping in Python (and other Selenium-supported programming languages):
- Search Engines: Several Search bot engines crawl billions of websites and analyze their content for gathering meaningful search results. Search engine crawling is often called spidering. Spiders navigate through the web by downloading web pages and following links on these pages to find new pages available for their users. Then, they rank them according to different factors like keywords, content uniqueness, page freshness, and user engagement.
- E-commerce (Price Comparison): Price comparison websites use bots to fetch price rates from different e-commerce websites. Python Web Scraping is a reliable and efficient method of getting product data from target e-commerce sites according to your requirements. They acquire data by either building in-house web scraping methodologies or employing a DaaS (Data As A Service) provider that’ll provide the requisite data.
- Sentiment Analysis: Market research companies use Python Web Scraping for sentiment analysis. This kind of analysis helps companies gain customer insights, along with helping them understand how their customers behave to particular brands and products.
- Job Postings: Job listings for details about job openings and interviews are scraped from a collection of websites. The scraped information is then listed in one place so that it is seamlessly accessible to the users.
Read More– Get started with your easy Selenium Python tutorial!!!
Legality of Python Web Scraping?
This is a debatable topic since it entirely depends on the intent of web scraping and the target website from which the data is being scraped. Some websites allow web scraping while several don’t. To see whether a website permits web scraping or not, we have to look at the website’s “robots.txt” file. We can find this file by adding “/robots.txt” at the end of the URL that you want to scrape.
For example, if we want to scrape the LambdaTest website, we have to see the “robots.txt” file, which is at the URL https://www.lambdatest.com/robots.txt
|
1 2 3 4 |
User-agent: * Allow: / Sitemap: https://www.lambdatest.com/sitemap.xml |
Python Web Scraping
Getting started with web scraping in Python is easy since it provides tons of modules that ease the process of scraping websites. Here are some of the modules that you should be aware of to realize Python Web Scraping:
- Requests Library for Web Scraping
The requests library is used for making several types of HTTP requests like getting GET, POST, PUT, etc. Because of its simplicity and efficiency of use, it has a motto of “HTTP for Humans.”
But, we can’t directly parse HTML using the requests library. It uses the lxml library to parse HTML.
$ pip install requests - Beautiful Soup Library for Web Scraping
BeautifulSoup Library is one of the widely-used Python libraries for web scraping. It works by creating a parse tree for parsing HTML and XML documents. Beautiful Soup automatically transforms incoming documents to Unicode and outgoing documents to UTF-8. It uses a custom parser to implement idiomatic navigation methods to search and transform the parse tree.
$ pip install beautifulsoup4 - Scrapy Framework for Web Scraping
Scrapy is a web scraping framework created by Pablo Hoffman and Shane Evans, co-founders of Scrapinghub. It is a full-fledged web scraping tool that does all the heavy lifting and provides spider bots to crawl various websites and extract the data. With Scrapy, we can create spider bots, host them on Scrapy Hub, or use their APIs. It allows us to develop fully functional spiders in a few minutes. We can also add pipelines to process and store data.
Scrapy allows making the asynchronous request, which means it makes multiple HTTP requests simultaneously. This method saves a lot of time and increases our efficiency of scraping.
$ pip install Scrapy
Note: To further ease down the process of writing small tests, Python offers various tools and frameworks. Whether you are a Python beginner or an experienced programmer, pytest helps you write the tests you need and have them run in a reliable manner. For a quick overview on getting started with pytest, check out the video below from LambdaTest YouTube Channel.
Static and Dynamic Selenium and Python Web Scraping
There is a difference between static web pages and dynamic web pages. In a static web page, the content remains the same until someone changes them manually. On the other hand, the dynamic web page content of the page can differ for different visitors (e.g., content can change as per the geolocation, user profile, etc.). This increases its time complexity as dynamic web pages can render at the client-side, unlike static web pages, which render at the server-side.
The static web page content or HTML documents are downloaded locally, and data can be scraped using relevant scripts. On the other hand, dynamic web page content (or data) is generated uniquely for every request after the initial page load request. For that case, we need to perform the following several actions using the manual approach:
For this purpose, we need to automate websites, the same can be achieved using Selenium WebDriver.
Scraping Dynamic Web Page using Python and Selenium
Here are the prerequisites for realizing Selenium and Python Web Scraping:
- Beautifulsoup for scraping HTML content for websites:
$ pip install beautifulsoup4 - Parsing HTML content of websites:
$ pip install lxml - Selenium for automation:
- Installing Selenium using pip
$ pip install selenium - Install Selenium using conda
$ conda install -c conda-forge selenium
- Installing Selenium using pip
Read – What is Selenium & how to get started?
Importing modules for Selenium and Python Web Scraping
For demonstration, we would be using the LambdaTest Grid. Cloud-based Selenium Grid on LambdaTest lets you run Selenium automation tests on 2,000+ browsers and operating systems online. You can perform parallel testing at scale using the cloud-based Grid. Once you create an account on LambdaTest, make a note of the user-name & access-key from the LambdaTest profile section.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
import os from selenium.webdriver.common.keys import Keys from bs4 import BeautifulSoup as bs from lxml import html from selenium import webdriver from selenium.webdriver.common.by import By // get your user key from LambdaTest platform and import using environment variables // username = os.environ.get("LT_USERNAME") // access_key = os.environ.get("LT_ACCESS_KEY") // Username and Access Key assigned as String variables username = "user_name" access_key = "access_key" |
Now that we have imported all modules let’s get our hands dirty with Selenium and Python Web Scraping.
Locating elements for Selenium and Python Web Scraping
We would scrap the Blog Titles from the LambdaTest Blog Page. For this, we search for a particular topic and enter the required topic in the search bar.
The following Selenium Locators can be used for locating WebElements on the web page under test:
Here is an example of the usage of Selenium web locators to locate the search box on the page:
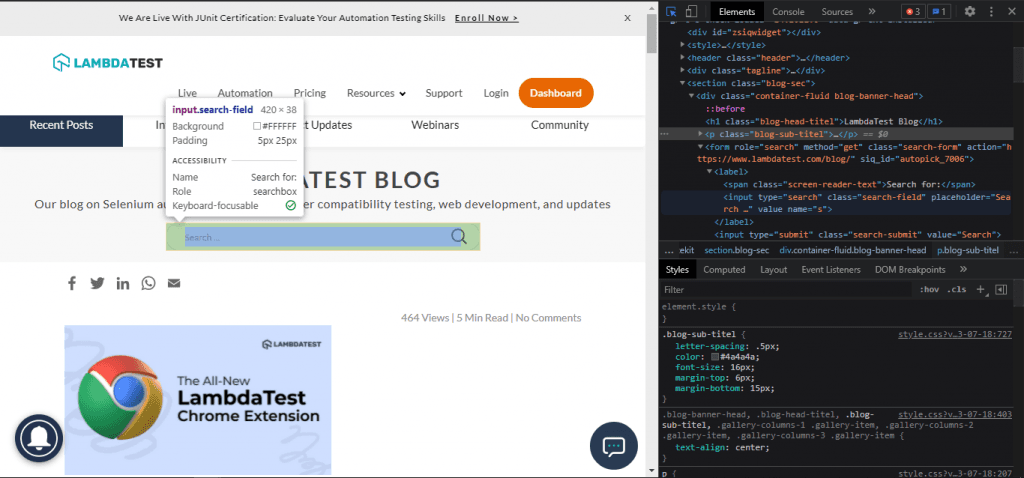
In this case, we would use the XPath method driver.find_element(By.XPATH) to locate the search box on the page.
|
1 2 3 4 5 6 7 8 9 10 11 |
driver.get("https://www.lambdatest.com/blog/") searchBarXpath = "/html[1]/body[1]/section[1]/div[1]/form[1]/label[1]/input[1]" # searching topic textbox = driver.find_element(By.XPATH, searchBarXpath) textbox.send_keys(topic) textbox.send_keys(Keys.ENTER) source = driver.page_source |
As we have got the content, we can parse it using lxml and beautifulsoup.
Read: A Complete Tutorial on Selenium Locators
Scraping titles using beautifulsoup
After parsing HTML source using lxml’s html.parser, we will find all h2 tags with class “blog-titel” and anchor tags inside them as these anchor tags contain the blog titles.
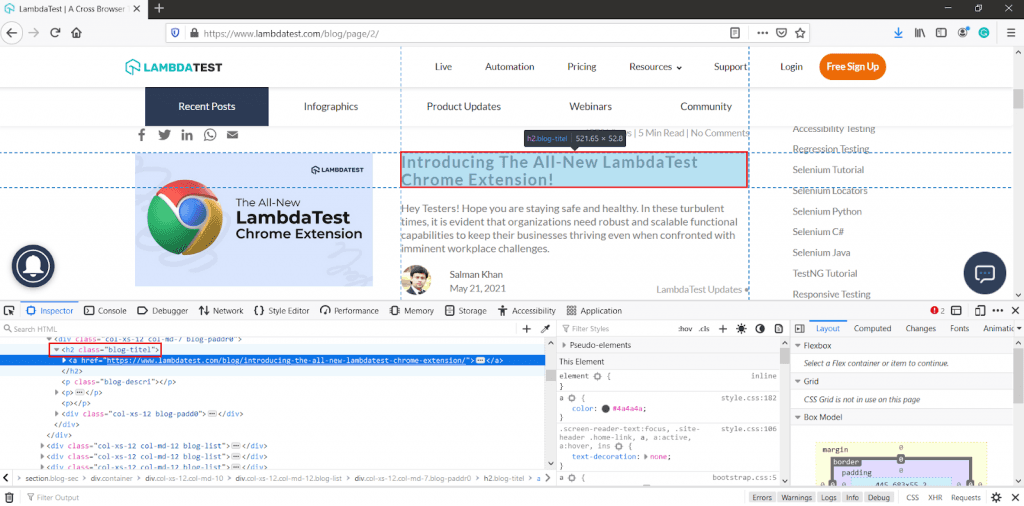
|
1 2 3 4 5 6 7 |
title_list = [] soup = bs(source,"html.parser") for h2 in soup.findAll("h2", class_="blog-titel"): for a in h2.findAll("a",href=True): title_list.append(a.text) return title_list |
Read – Scraping Dynamic Web Pages Using Selenium And C#
Putting it all together
Let’s combine the code to get the output.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
import os from selenium.webdriver.common.keys import Keys from bs4 import BeautifulSoup as bs from lxml import html from selenium import webdriver from selenium.webdriver.common.by import By // get your user key from LambdaTest platform and import using environment variables // username = os.environ.get("LT_USERNAME") // access_key = os.environ.get("LT_ACCESS_KEY") // Username and Access Key assigned as String variables username = "user_name" access_key = "access_key" class blogScraper: # Generate capabilities from here: https://www.lambdatest.com/capabilities-generator/ def setUp(self): capabilities = { "build" : "your build name", "name" : "your test name", "platform" : "Windows 10", "browserName" : "Chrome", "version" : "91.0", "selenium_version" : "3.11.0", "geoLocation" : "IN", "chrome.driver" : "91.0", "headless" : True } self.driver = webdriver.Remote( command_executor="https://{}:{}@hub.lambdatest.com/wd/hub".format(username, access_key), desired_capabilities= capabilities) def tearDown(self): self.driver.quit() def scrapTopic(self,topic): driver = self.driver # Url driver.get("https://www.lambdatest.com/blog/") searchBarXpath = "/html[1]/body[1]/section[1]/div[1]/form[1]/label[1]/input[1]" # searching topic textbox = driver.find_element_by_xpath(searchBarXpath) textbox.send_keys(topic) textbox.send_keys(Keys.ENTER) source = driver.page_source # scraping title title_list = [] soup = bs(source,"html.parser") for h2 in soup.findAll("h2", class_="blog-titel"): for a in h2.findAll("a",href=True): title_list.append(a.text) return title_list if __name__ == "__main__": obj = blogScraper() obj.setUp() print(obj.scrapTopic("scrap")) obj.tearDown() |
Here is the execution output:
|
1 |
['Scraping Dynamic Web Pages Using Selenium And C#', '9 Of The Best Java Testing Frameworks For 2021', 'The Best Alternatives to Jenkins for Developers', '10 Of The Best Chrome Extensions - How To Find XPath in Selenium', 'How To Take A Screenshot Using Python & Selenium?', 'Top 10 Java Unit Testing Frameworks for 2021', 'Agile Vs Waterfall Methodology', 'Why You Should Use Puppeteer For Testing'] |
Selenium is often essential to extract data from websites using lots of JavaScript as it’s an excellent tool to automate nearly anything on the web.
Read – Automation Testing with Selenium JavaScript [Tutorial]
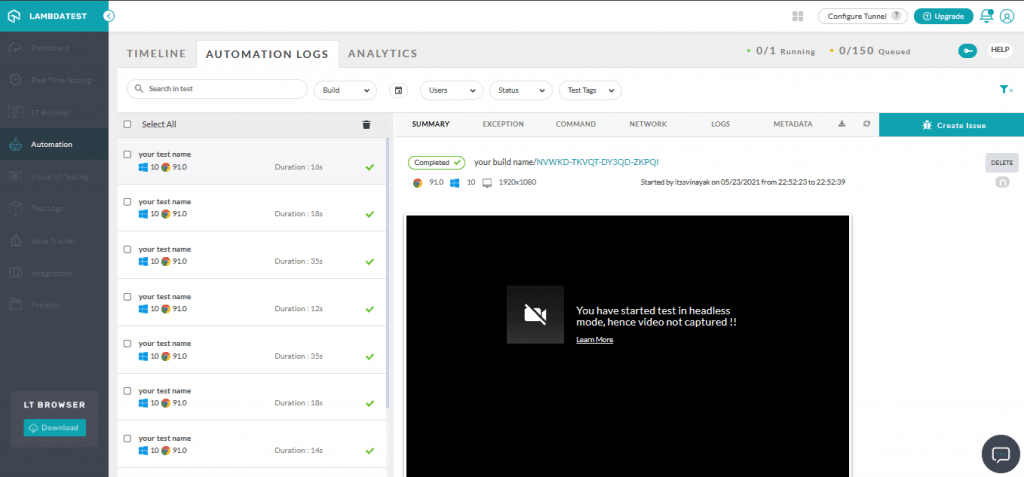
Here is the execution snapshot of our Python web automation tests on the LambdaTest Automation Dashboard:
Conclusion
In this blog on Selenium and Python Web Scraping, we deep-dived into web scraping as a technique that is extensively used by software developers for automating the extraction of data from websites. The purpose of web scraping is to allow companies and enterprises to manage information efficiently. There are a number of applications, such as VisualScrapper, HTMLAgilityPack, etc., that allow users to scrape data from static web pages. On the other hand, Selenium is the most preferred tool for dynamic web page scraping.
Test automation supports a variety of browsers and operating systems. LambdaTest offers a cloud-based Selenium Grid that makes it easy to perform cross browser testing at scale across different browsers, platforms, and resolutions.
Happy Scraping!


Author’s Profile
Vinayak Sharma
Full stack python developer and a tech enthusiast with strong communication and interpersonal skills. Highly adaptable to new environments, challenges, and increasing levels of responsibilities.
Blogs: 5
Got Questions? Drop them on LambdaTest Community. Visit now













